인덱스
인덱스(index)는 데이터를 빠르게 찾을 수 있도록 도와주는 도구로 클러스터형 인덱스(Clustered Index)와 보조 인덱스(Secondary Index)로 구분지을 수 있다.
클러스터형 인덱스(Clustered Index)
기본 키로 지정하면 자동 생성되며 테이블에 1개만 생성할 수 있고 자동으로 정렬된다.
보조 인덱스 (Secondary Index)
고유 키로 지정하면 자동 생성되며 테이블에 여러 개 생성할 수 있고 정렬되지 않는다.
인덱스 확인
use market_db;
create TABLE table1 (
col1 INT PRIMARY KEY ,
col2 INT,
col3 INT
);
show index from table1;위 쿼리를 활용해서 나온 결과에서 Key_name이 PRIMARY인 것이 클러스터형 인덱스이고 PRIMARY가 아닌 것이 보조 인덱스이다.

어떤 인덱스 사용하는지 확인

SELECT문을 사용해서 데이터를 조회할 때 어떤 인덱스를 사용해서 데이터를 조회하는지 알고 싶다면 SELECT문 앞에 EXPLAIN을 붙여서 실행하면 된다.
EXPLAIN SELECT * FROM player WHERE backnumber = 7;어떤 인덱스를 사용할지를 결정하는 것은 옵티마이저이다.
사용할 인덱스 명시
옵티마이저가 성능이 안나올 것 같아서 인덱스를 사용을 안하려고 하는데 내가 직접 특정 인덱스를 사용하고 싶다면 FROM 뒤에 USE INDEX를 사용하면 된다.
SELECT * FROM player USE INDEX(background_idx) WHERE backnumber = 7;인덱스 생성과 제거
생성
CREATE [UNIQUE] INDEX 인덱스_이름 on 테이블_이름(열_이름) [ASC | DESC];- UNIQUE : 생략하면 중복이 허용되는 인덱스가 생성이 된다. 만약에 사용할려면 기존 값들 중에서 중복된 값이 있으면 안된다.
제거
DROP INDEX 인덱스_이름 on 테이블_이름(열_이름);- 기본 키는 제거할 수 없다.
테이블 생성시 고유 인덱스 생성
고유 인덱스(Unique Index)란 인덱스의 값이 중복되지 않는다는 의미고, 단순 인덱스(Non-Unique Index)는 인덱스의 값이 중복되어도 된다는 의미입니다.
- Primary Key : 고유 인덱스 생성
- Unique : 고유 보조 인덱스 생성
use market_db;
create TABLE table2 (
col1 INT PRIMARY KEY,
col2 INT UNIQUE,
col3 INT UNIQUE
);
show INDEX FROM table2;
인덱스 주의사항 예제
다음과 같이 indexing된 테이블이 있다고 가정할 때 아래의 쿼리들은 각각
SELECT * FROM player WHERE team_id = 110; # index 사용
SELECT * FROM player WHERE team_id = 110 AND backnumber = 7; # index 사용
SELECT * FROM player WHERE backnumber = 110; # Full Scan
SELECT * FROM player WHERE team_id = 110 or backnumber = 110; # Full Scan이 된다. 이유는 backnumber 자체는 index로 정렬된 데이터가 아니기 때문에 backnumber에 대한 데이터만 조회를 해야하는 상황에서는 Full Scan을 해야하는 것이다.
인덱스의 단점
- 인덱스를 여러 개를 만들게 되면 그 인덱스를 위한 저장 공간이 필요하다.
- 데이터를 추가, 수정, 삭제할 때 인덱스도 같이 수정해야 하기 때문에 성능이 떨어질 수 있다.
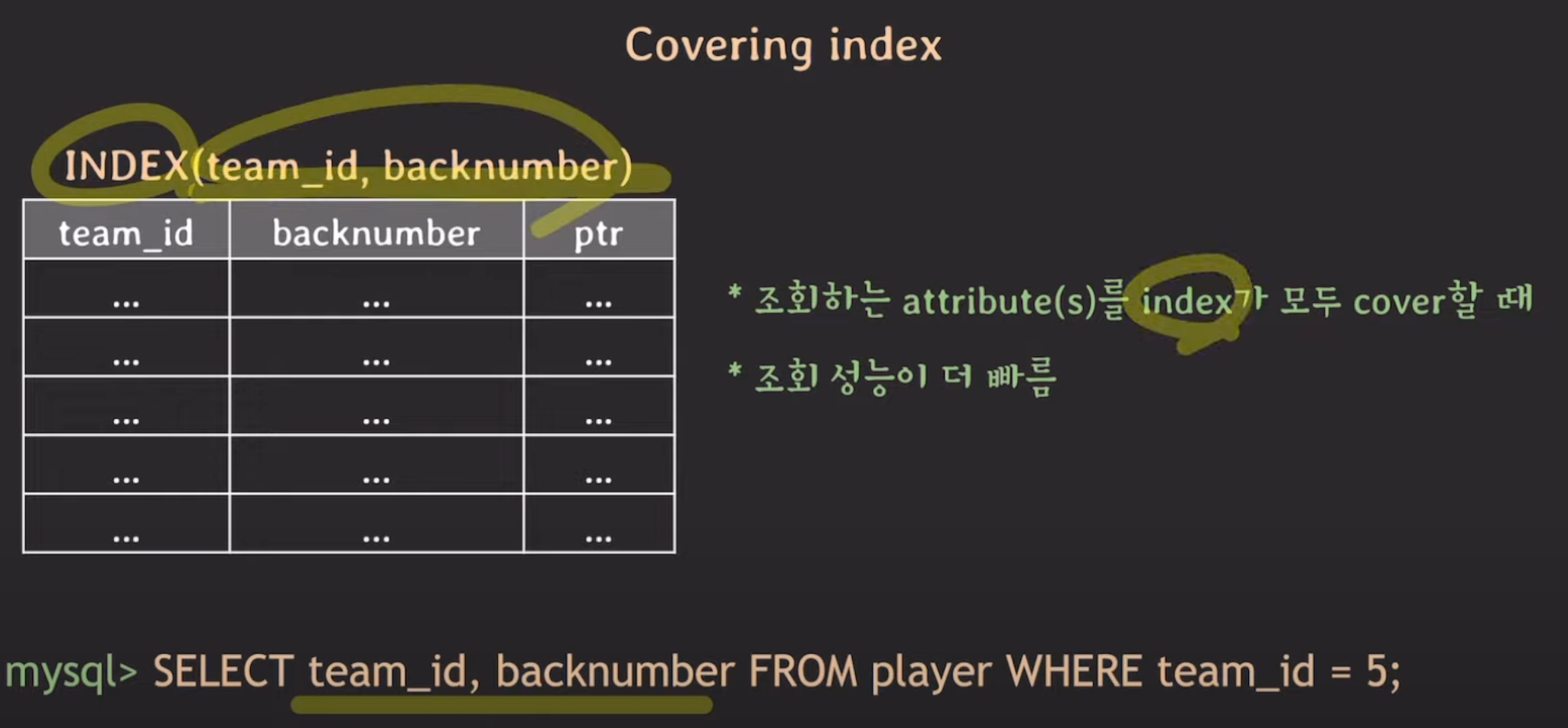
Covering Index
조회하는 attribute를 index가 모두 cover할 때 조회 성능이 더 빠른데, 이를 Covering Index라고 한다.