출처 - https://github.com/jmxx219/CS-Study (opens in a new tab)
캐시 메모리
캐시 메모리

- 캐시 메모리 정의
- CPU와 메인 메모리 사이에 위치한 임시 저장 장치
- 메인 메모리로부터 전송된 데이터의 일부 또는 앞으로 전송될 데이터의 일부를 저장
- 배경
- 메모리 계층 구조에서 발생하는 성능 격차 해결
- 현대 CPU는 매우 빠르게 작동하지만, 메인 메모리 접근 속도는 상대적으로 느림
- 이로 인한 데이터 가져오기 지연이 성능 저하를 초래
- 캐시 메모리의 역할
- CPU와 메인 메모리 사이의 속도 차이 완화
- 자주 사용하는 데이터를 빠른 캐시 메모리에 저장
- CPU가 메인 메모리 대신 캐시 메모리에서 데이터를 빠르게 액세스 가능
L1,L2,L3 캐시
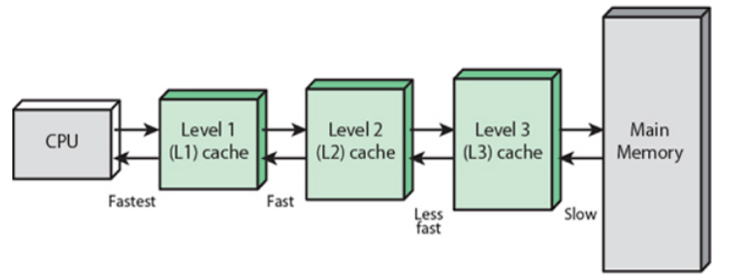
- L1 캐시(Level 1)
- CPU 코어 내부에 위치한다
- 가장 빠르지만 용량이 작다
- L2 캐시(Level 2)
- CPU 칩 내부에 위치하며, 각각의 코어나 코어 그룹에 할당될 수 있다
- L1보다는 느리지만 용량이 크다
- L3 캐시(Level 3)
- 모든 CPU 코어가 공유하는 캐시로 CPU 칩 내부에 위치한다
- L2 보다는 느리지만 더 큰 용량을 가진다.
캐시 데이터 관리

- 캐시 라인(or 캐시 블록):
- 캐시에서의 데이터 저장 단위. 일반적으로 캐시 라인은 여러 바이트로 구성된다. ex - 32바이트. 64바이트
- 특정 메모리 주소 범위의 데이터를 저장한다
- 메모리로부터 데이터를 가져올 때는 이 캐시 라인 단위로 올라온다
- CPU가 특정 주소의 데이터에 접근하려 할 때, 해당 주소를 포함하는 전체 캐시 라인이 캐시로 가져와진다.
- 교체 정책 (Replacement Policy):
- 캐시가 꽉 찼을 때 어떤 캐시 라인을 교체할지를 결정하는 알고리즘
LRU (Least Recently Used): 가장 오랫동안 사용되지 않은 캐시 라인을 교체한다.FIFO (First-In, First-Out): 가장 먼저 캐시에 올라온 라인을 교체한다.Random: 무작위의 캐시 라인을 교체한다.
- 캐시가 꽉 찼을 때 어떤 캐시 라인을 교체할지를 결정하는 알고리즘
- 쓰기 정책 (Write Policy):
- CPU가 데이터를 쓰려 할 때, 해당 데이터의 캐시와 주기억장치의 동기화 방법을 결정하는 정책.
Write Through: 데이터를 캐시와 메인 메모리에 동시에 기록한다.Write Back: 캐시에만 먼저 데이터를 기록하고, 특정 조건에서 메인 메모리에 업데이트한다.
- CPU가 데이터를 쓰려 할 때, 해당 데이터의 캐시와 주기억장치의 동기화 방법을 결정하는 정책.
캐시 간 동기화
- 캐시 동기화란 여러 캐시가 동일한 메모리 위치에 대한 데이터를 동시에 가질 때, 그 데이터의 일관성을 유지하는 것을 의미한다.
- 예를 들어, 한 프로세서의 캐시가 특정 메모리 주소의 값을 변경했을 때, 다른 캐시들도 이 변경을 인식하고 자신의 데이터를 갱신해야 한다.
- 일관성을 위해 여러 프로토콜이 사용되며, MESI 프로토콜 (opens in a new tab)이 대표적이다.
MESI 프로토콜 요약
-
MESI 프로토콜은 캐시 일관성을 유지하기 위한 대표적인 프로토콜 중 하나이다.
-
이름 "MESI"는 프로토콜에서 사용되는 네 가지 상태를 나타낸다.
-
M (Modified): 현재 캐시에 있는 값이 메모리의 값과 다르며, 변경된 값이 아직 메모리에 반영되지 않았다.
-
E (Exclusive): 현재 캐시에 있는 값이 메모리의 값과 일치하며, 다른 어떤 캐시에도 이 값을 갖고 있지 않았다.
-
S (Shared): 현재 캐시에 있는 값이 메모리의 값과 일치하며, 다른 캐시들도 이 값을 갖고 있을 수 있다.
-
I (Invalid): 현재 캐시의 값이 유효하지 않다.
-
-
캐시가 특정 메모리 주소의 데이터에 접근하려고 할 때, 해당 데이터의 상태에 따라 다음과 같은 동작이 수행된다.
- 읽기 연산:
- Miss: 데이터가 캐시에 없으면 메모리에서 가져오고, 해당 데이터가 다른 캐시에 "Exclusive"나 "Modified" 상태로 있지 않으면 "Shared" 상태로 설정한다. 그렇지 않으면 "Exclusive" 상태로 설정한다
- Hit: 데이터가 "Shared"나 "Exclusive" 상태면 그대로 사용한다
- 쓰기 연산:
- Miss: 데이터가 캐시에 없으면 메모리에서 가져와 "Modified" 상태로 설정한다
- Hit: 데이터가 "Exclusive" 상태면 "Modified" 상태로 변경한다
- 읽기 연산:
데이터의 상태 변경은 버스 연산 (예: 버스 읽기, 버스 쓰기)을 통해 다른 캐시들에게도 알려진다. 이를 통해 모든 캐시가 동일한 메모리 위치의 최신 값을 유지할 수 있다.
캐시 메모리 맵핑
직접 매핑 (Direct-mapped)
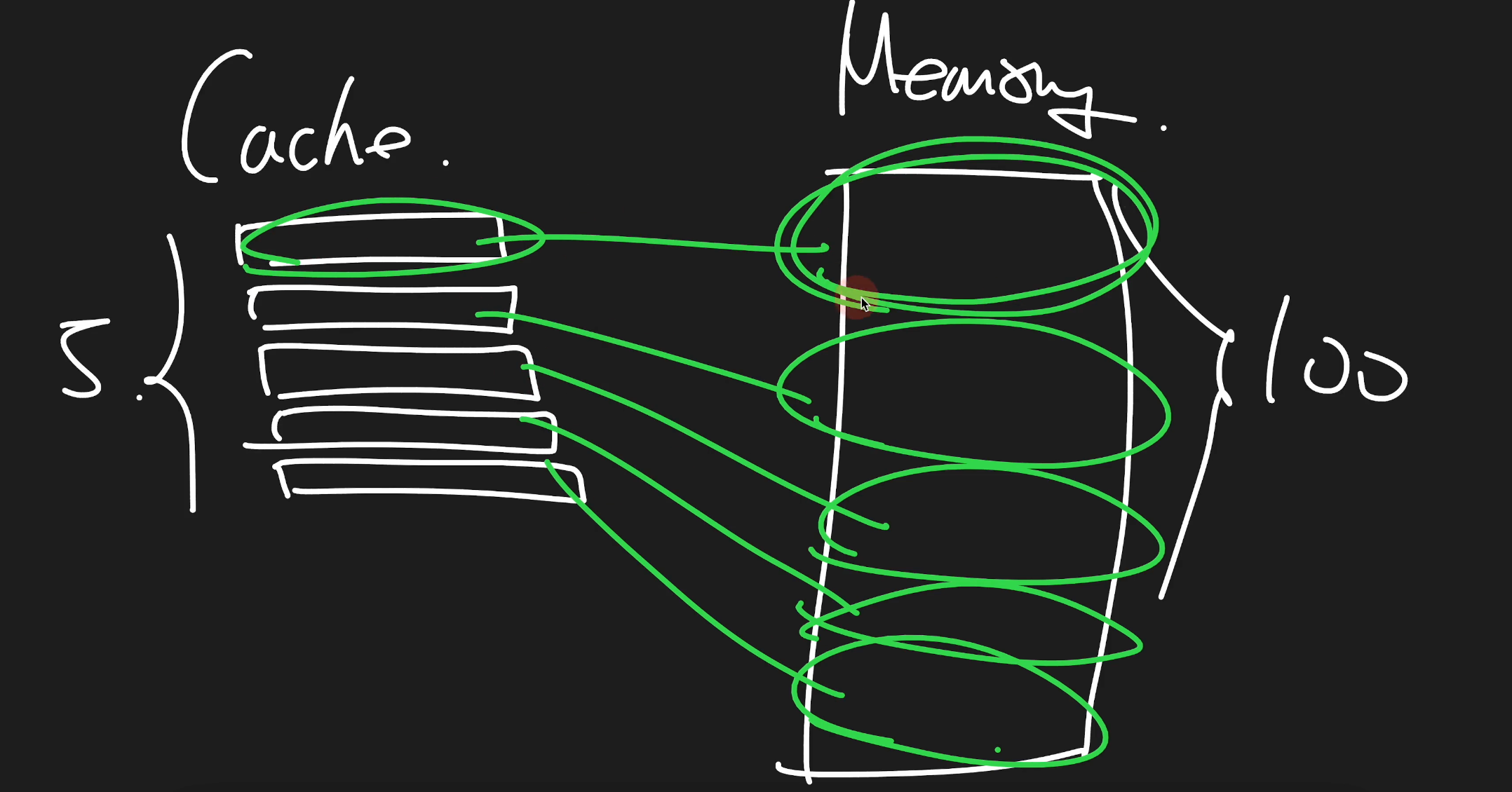
- 특징
- 주 메모리의 크기가 더 작기 때문에 캐시의 라인의 수 만큼 주 메모리를 블록으로 나누어 사용한다
- 주 메모리의 각 블록은 캐시의 한 라인에만 매핑될 수 있다
- tag, bd(block distance), D로 세분화해서 bd가 같은 라인만 맵핑되게 되는데 예를 들어서 메인 메모리에 bd에 해당하는 데이터가 10개 있는데 그 데이터를 번갈아가고 싶다면 캐시 메모리에 bd에 해당하는 라인에만 들어올 수 있다는 것이다
- 이로 인해서 스와핑이 빈번하고 다른 라인이 사용되지 않는다는 단점이 발생할 수 있다
- 장점
- 간단한 구조로 구현 가능하며, 캐시 접근 시간이 빠르다
- 주소를 통해 직접적으로 해당 캐시 라인을 찾을 수 있다
완전 연관 매핑 (Fully Associative)
- 특징:
- 주 메모리의 블록은 캐시 내의 어떤 라인에도 매핑될 수 있다
- 데이터를 찾을 때 캐시의 모든 라인을 동시에 검사한다 (태그 비교)
- 스와핑이 덜 일어나겠지만 캐시의 모든 블록을 탐색해야 해서 속도가 직접매핑보다 느리다
- 장점:
- 최적의 캐시 활용이 가능하며, 충돌 문제가 없다
- 잦은 데이터 교체 없이 다양한 데이터를 캐시에 유지할 수 있다
- 단점:
- 모든 라인을 검사해야 하므로, 태그 비교 회로가 복잡하고, 캐시 접근 시간이 길어질 수 있다
세트 연관 매핑 (Set Associative)
- 특징:
- 캐시는 여러 세트로 나뉘며, 각 세트에는 여러 개의 라인이 있다
- 주 메모리의 블록은 특정 세트에 매핑되지만, 그 세트 내에서는 어떤 라인에도 매핑될 수 있다
- 쉽게 말해서 캐쉬 내에 각 라인마다 bd가 한개가 아니라 여러개가 있어서 그 중에 하나를 선택해서 넣는 방식이다
- 장점:
- 직접 매핑의 간결함과 완전 연관 매핑의 유연성을 조합한 방식이다
- 충돌을 줄이면서도 태그 비교 회로의 복잡성을 감소시킬 수 있다
- 단점:
- 여전히 특정 세트 내에서 충돌이 발생할 수 있다
- 구현 복잡성이 직접 매핑보다는 높다
캐시 지역성
프로그램의 실행 특성상 연속적으로 동작하게 되므로, 한 번 접근한 데이터나 그 주변의 데이터를 곧 다시 사용할 가능성이 높다.
- 시간적 지역성 (Temporal Locality)
- 한 번 접근된 데이터에 대해 가까운 미래에 다시 접근될 확률이 높다.
- 예를 들어, 반복문 내에서의 변수 접근, 스택의 최상위 데이터 등이 이에 해당한다.
- 공간적 지역성 (Spatial Locality)
- 한 번 접근된 데이터의 주변 데이터에 대해 가까운 미래에 접근될 확률이 높다.
- 예를 들어, 배열을 순차적으로 처리하는 경우, 현재 위치의 다음 배열 요소에 접근하는 경우가 이에 해당한다
캐시의 지역성을 기반으로, 이차원 배열을 가로/세로로 탐색했을 때의 성능 차이
컴퓨터에서 메모리는 일차적원적인 구조를 가진다. 이차원 배열도 실제로는 이 일차원 메모리에 연속적으로 저장된다. 예를 들어 2x2 이차원 베열이 있다면 다음과 같이 저장된다
[0][0], [0][1], [1][0], [1][1]
- 가로로 탐색(배열의 행을 연속적으로 탐색하는 것)
[0][0] -> [0][1] -> ...- 메모리에 연속적으로 저장된 데이터를 순차적으로 접근하므로 공간적 지역성이 높게 된다
- 따라서 캐시 히트율이 높아져 성능이 좋아질 가능성이 크다
- 세로로 탐색(배열의 열을 연속적으로 탐색하는 것)
[0][0] -> [1][0] -> ...- 메모리에 연속적으로 저장되어 있지 않는 데이터에 접근하게 되므로 공간적 지역성을 활용하기 어렵다
- 따라서 캐시 미스율이 가로로 탐색하는 것보다 높아질 수 있다
메모리 계층성
- 메모리 계층성은 컴퓨터 시스템 내에서 다양한 메모리와 스토리지 유형이 속도, 크기, 비용 등의 특성에 따라 계층적으로 구성되어 있다는 개념이다
- 이 계층 구조는 최상위의 빠른 속도와 작은 크기를 가진 메모리부터 최하위의 느린 속도와 큰 크기를 가진 스토리지까지 범위를 갖는다
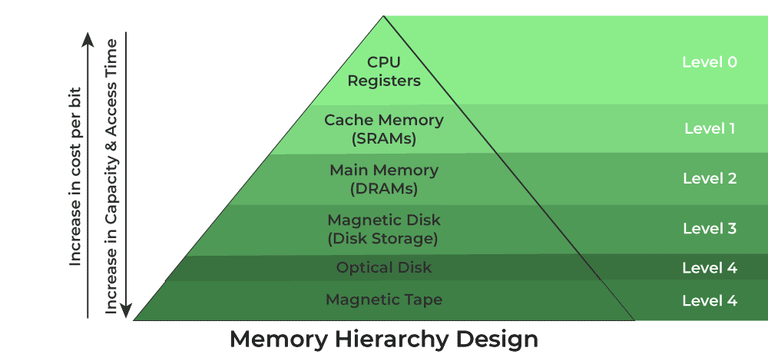
- 레지스터 (Registers):
- CPU 내에 위치.
- 매우 빠르고 크기가 매우 작음.
- 비용이 가장 높음.
- 캐시 메모리 (Cache Memory):
- Level 1 (L1), Level 2 (L2), Level 3 (L3) 등 여러 레벨로 나뉨.
- CPU에 가깝게 위치하며, 레지스터보다는 크지만 느림.
- 비용은 레지스터보다 낮지만 주 메모리보다 높음.
- 주 메모리 (Main Memory or RAM):
- 대부분의 응용 프로그램과 데이터가 로드되는 장소.
- 캐시보다는 느리지만, 보조 메모리보다 빠름.
- 비용은 캐시보다 낮음.
- 보조 메모리 (Secondary Memory):
- 하드 드라이브 (HDD), 솔리드 스테이트 드라이브 (SSD) 등.
- 주 메모리보다 훨씬 크지만 느림.
- 보통 데이터의 지속적인 저장을 위해 사용됨.
- 테이프 드라이브 (Tertiary Memory):
- 아카이브나 백업용으로 사용.
- 매우 느리지만, 대용량의 데이터를 저장하기에 적합.
빠른 메모리는 비용이 높기 때문에 크기를 작게 유지하며, 느린 메모리는 비용이 낮기 때문에 크기를 크게 유지한다. 프로그램의 실행 중에는 자주 접근되는 데이터나 명령어는 빠른 메모리 (예: 캐시나 레지스터)에 저장되고, 자주 접근되지 않는 데이터는 느린 메모리 (예: 하드 드라이브)에 저장된다.