RealMySQL 09장 옵티마이저와 힌트
개요
쿼리 실행 절차
- SQL 파서 : SQL 파싱
- 사용자로부터 요청된 SQL 문장을 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리(파스 트리)
- SQL의 파싱 정보(파스 트리)를 확인하면서 어떤 테이블부터 읽고 어떤 인덱스를 이용해 테이블을 읽을지 선택
- 두 번째 단계에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져옴
- 옵티마이저 : 최적화 및 실행 계획 수립
- 불필요한 조건 제거 및 복잡한 연산의 단순화
- 여러 테이블의 조인이 있는 경우 순서대로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스를 결정
- 가져온 레코드들을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
- 실행 엔진 : 실행 계획에 따라 데이터를 읽고 처리
- 수립된 실행 계획대로 스토리지 엔진에 레코드를 읽어오도록 요청하고, MySQL 엔진에서는 스토리지 엔진으로부터 받은 레코드를 조인하거나 정렬하는 작업을 수행
옵티마이저의 종류
- 규칙 기반 최적화(오라클) : 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립하는 방식
- 인덱스의 통계 정보가 거의 없고 상대적으로 느린 CPU 연산 탓에 비용 계산 과정이 부담스럽다는 이유로 사용되던 최적화 방법
- 비용 기반 최적화 : 각 단위 작업의 비용 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출
- 현재 MySQL을 포함한 대부분의 RDBMS가 사용
기본 데이터 처리
리드 어헤드
- 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB의 버퍼 풀에 가져다 두는 것을 의미
- 처음 몇 개의 데이터 페이즈는 포그라운드 스레드(Foreground Thread, 클라이언트 스레드)가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘김
- 백그라운드 스레드가 읽기를 넘겨받는 시점부터는 한 번에 4개 또는 8개씩 페이지를 읽으면서 계속 그 수를 증가
- 한 번에 최대 64개의 데이터 페이지까지 읽어서 버퍼 풀이 저장
- 포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 상당히 빨리 처리됨
병렬 처리
- innodb_parallel_read_threads라는 시스템 변수를 이용해 하나의 쿼리를 최대 몇 개의 스레드를 이용해서 처리할지를 변경할 수 있음
- 병렬 처리용 스레드 개수를 아무리 늘리더라도 서버에 장착된 CPU의 코어 개수를 넘어서는 경우에는 오히려 성능이 떨어질 수도 있음
SET GLOBAL innodb_parallel_read_threads = 4;Order By 처리
- 파일 소트 : 인덱스를 이용하지 않고 데이터를 정렬하는 방식
- 인덱스 소트 : 인덱스를 이용해서 데이터를 정렬하는 방식
소트 버퍼
- MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당 받아서 사용하는데 이 공간을 소트 버퍼라고 함
- 정렬해야 할 레코드의 크기에 따라 가변적으로 증가하지만 최대 사용 가능한 소트 버퍼의 공간을 sort_buffer_size라는 시스템 변수로 설정
- 정렬해야 할 레코드의 건수가 소트 버퍼로 할당된 공간보다 크다면
- 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하는데, 이 과정에서 임시 저장을 위해 디스크를 사용
- 분할 한 다음에 정렬하고 디스크에 쓰고 또 다음 분할을 정렬하고 디스크에 쓰고 하기 때문에 속도가 느림
- 소트 버퍼의 크기는 256KB에서 8MB 사이에서 최적의 성능을 보임
- 근거 : 저자의 경험
- sort_buffer_size가 너무 크면 큰 메모리 공간 할당 때문에 성능이 훨씬 떨어질 수 도 있다고 함
- 운영체제(OS)는 프로그램 요청 시 메모리를 동적으로 할당하며, 큰 메모리를 할당하려면 연속된 공간을 찾는 데 시간이 걸리고 CPU 리소스를 소모
-
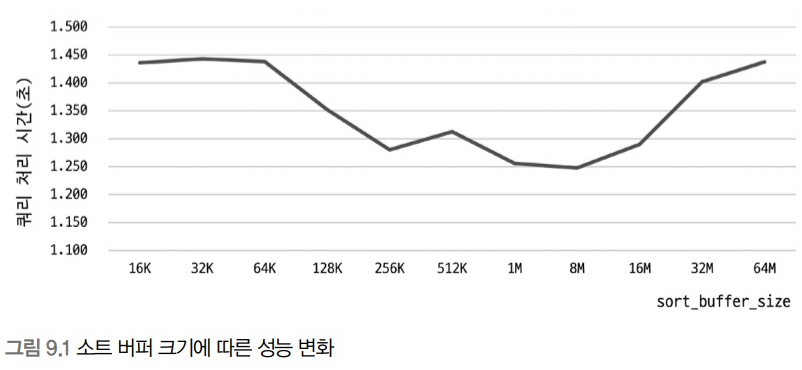
- 소트 버퍼를 크게 설정하면 디스크 읽기와 쓰기 사용량을 줄일 수 있음
- 대량 데이터의 정렬이 필요한 경우 해당 세션의 소트 버퍼만 일시적으로 늘려서 쿼리를 실행하고 다시 줄이는 것도 좋은 방법
- 해당 세션만 줄이는 방법 👇
-
SET SESSION sort_buffer_size = <크기>;
정렬 알고리즘
- 싱글 패스 : 정렬해야할 모든 컬럼을 다 메모리에 올리고 정렬하는 방식
- 더 많은 소트 버퍼 공간이 필요
- 일반적으로 이 방식을 주로 사용
- 레코드의 크기가 max_length_for_sort_data보다 작을 때 사용
- BLOB이나 TEXT 타입의 컬럼이 SELECT 대상에 포함되면 사용 불가
- 투 패스 : 정렬 대상과 PK만 소트 버퍼에 담아서 정렬을 수행하고, 정렬된 순서대로 다시 PK로 테이블을 읽어서 SELECT 하는 방식
select * 과 같은 쿼리를 많이 쓰는데 이런 쿼리는 정렬 성능에 좋지 못함
정렬 방식
- 인덱스를 이용한 정렬
- 조인의 드라이빙 테이블만 정렬
- 조인을 실행하기 전에 첫 번째 테이블의 레코드를 먼저 정렬한 다음 조인을 실행
-
SELECT * FROM employees e, salaries s WHERE e.emp_no = s.emp_no AND e.emp_no BETWEEN 10002 AND 10010 ORDER BY e.emp_no; - 위 쿼리의 경우 employees 테이블을 드라이빙 테이블로 선택하고 employees 테이블을 먼저 정렬한 다음 조인을 실행
- 임시 테이블을 이용한 정렬
- 2개 이상의 테이블을 조인해서 그 결과를 정렬해야 하는 경우 임시테이블을 사용해서 정렬을 해야 함
-
SELECT * FROM employees e, salaries s WHERE e.emp_no = s.emp_no AND e.emp_no BETWEEN 10002 AND 10010 ORDER BY e.emp_no, s.salary; - 정렬이 수행되기 전 salaries 테이블을 읽어야 하므로 이 쿼리는 조인된 데이터를 가지고 정렬할 수 밖에 없음
정렬 방식의 성능 비교
- order by나 group by 같은 작업은 where 조건을 만족하는 레코드를 limit 건수만큼만 가져와서는 처리할 수 없음
- 우선 조건을 만족하는 레코드를 모두 가져와서 정렬을 수행하거나 그루핑 작업을 실행해야만 비로소 limit으로 건수를 제한할 수 있음
스트리밍 방식 vs 버퍼링 방식
- 스트리밍 방식
- 서버 쪽에서 처리할 데이터가 얼마인지 관계없이 조건에 일치하는 레코드가 검색될 때마다 바로바로 클라이언트로 전송해주는 방식을 의미
- 버퍼링 방식
- order by나 group by 같은 처리는 쿼리의 결과가 스트리밍되는 것을 불가능하게 함
- 그래서 이와 같은 방식을 스트리밍 방식의 반대되는 개념인 버퍼링 방식이라고 함
- order by나 group by 같은 처리는 쿼리의 결과가 스트리밍되는 것을 불가능하게 함
- JDBC의 처리
- JDBC는 마지막 레코드가 전달될 때까지 기다렸다가 모든 결과를 전달받으면 그때서야 비로소 클라이언트의 애플리케이션에 반환함
- 전체 처리 시간이 짧고 MySQL 서버와의 통신 횟수가 적어 자원 소모가 줄어들기 때문
- 아주 대량의 데이터를 가져와야 할 때는 MySQL 서버와 JDBC 간의 전송 방식을 스트리밍 방식으로 변경할 수 있음
-
// JDBC URL useCursorFetch=true 옵션을 사용하면 스트리밍 방식으로 데이터를 가져올 수 있음 jdbc:mysql://localhost:3306/employees?useCursorFetch=true
- JDBC는 마지막 레코드가 전달될 때까지 기다렸다가 모든 결과를 전달받으면 그때서야 비로소 클라이언트의 애플리케이션에 반환함
Group By 처리
- GROUP BY에 사용된 조건은 인덱스를 사용해 처리될 수 없으므로 HAVING 절을 튜닝하려고 인덱스를 생성하거나 다른 방법을 고민할 필요는 없음
- GROUP BY도 인덱스 스캔 또는 루스 인덱스 스캔처럼 동작할 수 있다 함
- 아래 쿼리도 인덱스 루스 스캔처럼 동작 가능
-
// 인덱스는 (emp_no, from_date)로 생성되어 있음 explain select emp_no from salaries where from_date='1985-06-26' group by emp_no;
DISTINCT 처리
SELECT DISTINCT
SELECT DISTINCT emp_no FROM salaries;
SELECT emp_no FROM salaries GROUP BY emp_no;- DISTINCT는 SELECT하는 레코드(튜플)을 유니크하게 SELECT하는 것이지, 특정 컬럼만 유니크하게 조회하는 것이 아님
SELECT DISTINCT first_name, last_name FROM employees;- first_name만 유니크한 것을 가져오는 것이 아니라 (first_name, last_name) 조합 전체가 유니크한 레코드를 가져옴
- SELECT절에 사용된 DISTINCT 키워드는 조회되는 모든 칼럼에 영향을 미침
- 절대로 SELECT하는 여러 칼럼 중에서 일부 칼럼만 유니크하게 조회하는 것은 아님
집합함수와 함께 사용된 DISTINCT
EXPLAIN SELECT COUNT(DISTINCT s.salary)
FROM employees e, salaries s
WHERE e.emp_no = s.emp_no
AND e.emp_no BETWEEN 10001 AND 10010;- employees 테이블과 salaries 테이블을 조인한 결과에서 salary 칼럼의 값만 저장하기 위한 임시 테이블을 만들어서 사용
- 임시 테이블의 salary 칼럼에는 유니크 인덱스가 생성되기 때문에 레코드 건수가 많아진다면 상당히 느려질 수 있음
내부 임시 테이블 활용
- MySQL 엔진이 사용하는 임시 테이블은 처음에는 메모리에 생성됐다가 테이블의 크기가 커지면 디스크로 옮겨짐
- 특정 예외 메모리를 거치지 않고 바로 디스크에 임시 테이블이 만들어지기도 함
메모리 임시 테이블과 디스크 임시 테이블
- MySQL 8.0 버전 이전에는 MyISAM 스토리지 엔진을 이용했지만 8.0 버전부터는 TempTable이라는 스토리지 엔진을 사용하고, 디스크에 저장되는 임시 테이블은 InnoDB 스토리지 엔진을 사용
- MEMORY 스토리지 엔진은 VARBINARY나 VARCHAR 같은 가변 길이 타입을 지원하지 못하기 때문에 임시 테이블이 메모리에 만들어지면 가변 길이 타입의 경우 최대 길이만큼 메모리를 할당해서 사용
- 👉 메모리 낭비가 심해지는 구조
- 디스크에 저장될 때는 MMAP 파일 또는 InnoDB 테이블로 저장됨
- MMAP 파일이 InnoDB 테이블로 전환하는 것보다 오버헤드가 적기 때문
- 메모리 공간의 크기는 tmp_table_size 시스템 변수로 설정 가능하며 기본은 1GB
- 메모리의 TempTable 크기가 1GB를 넘어가면 디스크의 MMAP 파일로 전환
임시 테이블이 필요한 쿼리
- 주로 인덱스를 사용하지 못하는 경우
- ORDER BY와 GROUP BY에 명시된 칼럼이 다른 쿼리
예시
SELECT department_id, COUNT(*) AS employee_count
FROM employees
GROUP BY department_id
ORDER BY employee_count DESC;- ORDER BY나 GROUP BY에 명시된 조인의 순서상 첫 번째 테이블이 아닌 쿼리
예시
SELECT e.id, e.name, d.department_name
FROM employees e
JOIN departments d ON e.department_id = d.id
GROUP BY d.department_name
ORDER BY e.name;- DISTINCT와 ORDER BY가 동시에 존재하는 경우 또는 DISTINCT가 인덱스로 처리되지 못하는 쿼리
SELECT DISTINCT department_id
FROM employees
ORDER BY hire_date DESC;- UNION이나 UNION DISTINCT가 사용된 쿼리(select_type 칼럼이 UNION RESULT인 경우)
SELECT department_id
FROM employees
WHERE salary > 5000
UNION DISTINCT
SELECT department_id
FROM managers;- 쿼리의 실행 계획에서 select_type이 DERIVED인 경우
SELECT derived_table.department_id, COUNT(*) AS employee_count
FROM (
SELECT department_id, salary
FROM employees
WHERE salary > 5000
) AS derived_table
GROUP BY derived_table.department_id;고급 최적화
옵티마이저 스위치 옵션
| 옵티마이저 스위치 이름 | 기본값 | 설명 |
|---|---|---|
batched_key_access | off | BKA 조인 알고리즘을 사용하지 여부 설정 |
block_nested_loop | on | Block Nested Loop 조인 알고리즘 사용 여부 설정 |
engine_condition_pushdown | on | Engine Condition Pushdown 기능을 사용하지 여부 설정 |
index_condition_pushdown | on | Index Condition Pushdown 기능을 사용하지 여부 설정 |
use_index_extensions | on | Index Extension 최적화를 사용하지 여부 설정 |
index_merge | on | Index Merge 최적화를 사용하지 여부 설정 |
index_merge_intersection | on | Index Merge Intersection 최적화를 사용하지 여부 설정 |
index_merge_sort_union | on | Index Merge Sort Union 최적화를 사용하지 여부 설정 |
index_merge_union | on | Index Merge Union 최적화를 사용하지 여부 설정 |
mrr | on | MRR 최적화를 사용하지 여부 설정 |
mrr_cost_based | on | 비용 기반의 MRR 최적화를 사용하지 여부 설정 |
semijoin | on | 세미 조인 최적화를 사용하지 여부 설정 |
firstmatch | on | FirstMatch 세미 조인 최적화를 사용하지 여부 설정 |
loosesc | on | LooseScan 세미 조인 최적화를 사용하지 여부 설정 |
materialization | on | Materialization 최적화를 사용하지 여부 설정 (Materialization 세미 조인 포함) |
subquery_materialization_cost_based | on | 비용 기반의 Materialization 최적화를 사용하지 여부 설정 |
-- // 전체 커넥션의 옵티마이저 스위치만 설정
SET GLOBAL optimizer_switch='index_merge=off, index_merge_union=on...';
-- // 현재 커넥션의 옵티마이저 스위치만 설정
SET SESSION optimizer_switch='index_merge=off, index_merge_union=on...';MRR과 배치 키 액세스
- MRR(Multi-Range Read) : 여러 개의 인덱스 레인지를 한 번에 메모리에 읽어오는 방식, 메뉴얼에서는 DS-MRR이라고도 함
- 👉 JOIN은 MySQL 엔진이 처리하는거기 때문에 원래는 한 건의 레코드씩 읽어와서 JOIN을 하는 방식으로 처리함
- 조인 대상 테이블 중 하나로부터 레코드를 읽어서 조인 버퍼에 버퍼링함
- 조인 버퍼에 레코드가 가득차면 비로소 MySQL 엔진은 버퍼링된 레코드를 스토리지 엔진으로 한 번에 요청해서 읽어옴
- 스토리지 엔진은 읽어야 할 레코드들을 데이터 페이지에 정렬된 순서로 접근해서 디스크의 데이터 페이지 읽기를 최소화
블록 네스티드 루프 조인인
- 조인 알고리즘에서 Block이라는 단어가 사용되면 조인용으로 별도의 버퍼가 사용됨
- 드라이빙 테이블은 한 번에 쭉 읽지만, 드리븐 테이블은 여러 번 읽음
- 블록 네스티드 루프 조인 예시 👇
-
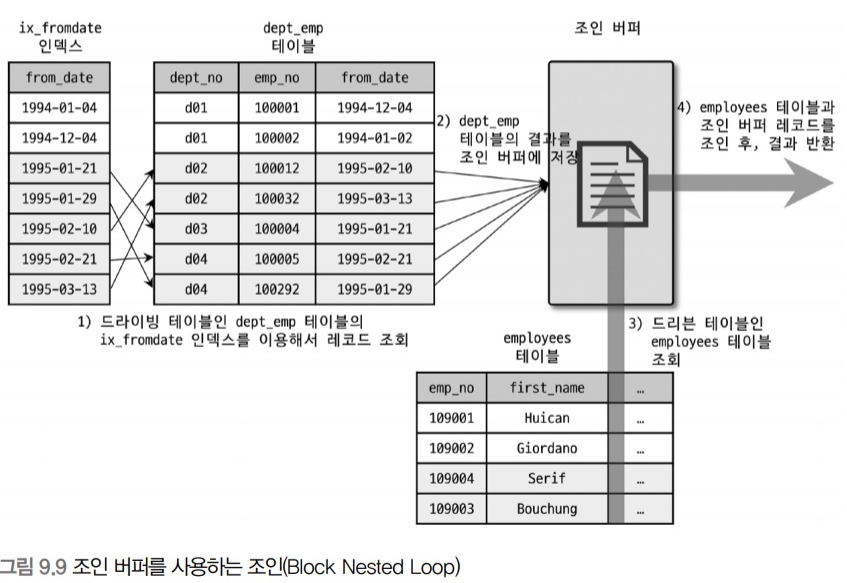
인덱스 컨디션 푸시다운
SELECT * FROM employees WHERE last_name = 'Action' AND first_name = '%sal';- 위 쿼리를 수행할 때 Record에서 last_name이 Action인 레코드 3개를 찾고 그 레코드를 다시 테이블에서 조회해서 first_name과 비교 작업을 함
- 인덱스를 비교하는 작업은 실제 InnoDB 스토리지 엔진이 수행하지만 테이블의 레코드에서 first_name 조건을 비교하는 작업은 MySQL이 수행하는 작업
- Action으로 검색된 레코드가 3건이라면 스토리지 엔진에서는 불필요한 2건의 테이블 읽기를 수행하게 됨
- MySQL 5.6 버전부터는 인덱스를 범위 제한 조건으로 사용하지 못한다고 하더라도 인덱스에 포함된 칼럼의 조건이 있다면 모두 같이 모아서 스토리지 엔진으로 전달할 수 있게 핸들러 API가 개선됨
- 인덱스가 걸려있지 않으면 해당 없음
인덱스 확장
인덱스 머지
- 인덱스를 이용해 쿼리를 실행하는 경우 대부분 옵티마이저는 테이블별로 하나의 인덱스만 사용하도록 실행 계획을 수립
- 인덱스 머지 실행 계획을 사용하면 하나의 테이블에 대해 2개 이상의 인덱스를 사용할 수 있음
인덱스 머지 - 교집합
- 아래 쿼리는 pk 인덱스와 first_name 인덱스를 사용해서 각각 탐색 후 교집합을 구함
--// first_name에 secondary index가 걸려있는 경우
EXPLAIN SELECT * FROM employees
WHERE first_name = 'Georgi' AND emp_no BETWEEN 10000 AND 20000;- 👇 index_merge_intersection 옵션을 끄는 방법
SET GLOBAL optimizer_switch='index_merge_intersection=off';
SET SESSION optimizer_switch='index_merge_intersection=off';
--// 현재 쿼리에서만 index_merge_intersection을 끄는 방법
SELECT /** SET_VAR(optimizer_switch='index_merge_intersection=off')*/ *
FROM employees WHERE first_name = 'Georgi' AND last_name = 'Facello';인덱스 머지 - 합집합
- 두 인덱스를 이용해서 각각 탐색 후 합집합을 구함
- 아래의 경우 first_name 인덱스와 hire_date 인덱스를 사용해서 각각 탐색 후 합집합을 구함
SELECT * FROM employees
WHERE first_name = 'Georgi' OR hire_date = '1987-03-31';
- 중복을 제거할 때 PQ를 사용하는데, peekLast()를 했을 때 중복이면 추가하지 않는 방식
인덱스 머지 - 정렬 후 합집합
SELECT * FROM employees
WHERE first_name = 'Matt' OR hire_date BETWEEN '1985-06-26' AND '1985-06-27';- 위 조건 식에서 first_name 조건은 정렬된 순서로 반환되지만 hire_date 조건은 정렬되지 않은 순서로 반환됨
- 그래서 각 집합을 emp_no 칼럼으로 정렬한 다음 중복 제거를 수행
세미 조인
- 단지 다른 테이블에서 조건에 일치하는 레코드가 있는지 없는지만 체크하는 형태의 쿼리를 세미 조인(Semi Join)이라고 함
SELECT *
FROM employees e
WHERE e.emp_no IN
(SELECT de.emp_no FROM dept_emp de WHERE de.dept_no = 'd001');- 다른 RDBMS에 익숙한 사용자라면 위 쿼리👆에서 서브쿼리 부분이 먼저 실행되고 그 다음 employees 테이블에서 일치하는 레코드만 검색할 것으로 기대했을 것임
- 하지만 MySQL 서버는 employees 테이블을 풀 스캔하면서 한 건 한 건 서브쿼리의 조건에 일치하는지 비교함
- 세미 조인을 최적화하기 위해서 5가지 정도의 최적화 기법이 있음
- Table Pull-out
- Duplicate Weedout
- FirstMatch
- LooseScan
- Materialization
Table Pull-out
- 서브쿼리에 사용될 테이블을 아우터 쿼리로 끄집어내서 쿼리를 조인 쿼리로 재작성하는 방식
SELECT * FROM employees e
WHERE e.emp_no In (SELECT de.emp_no FROM dept_emp de WHERE de.dept_no = 'd001');- 위 쿼리👆는 아래👇와 같이 변경됨
- 변경됐는지 확인할려면 SHOW WARNINGS를 명령어를 사용해서 최근 재작성된 쿼리를 확인
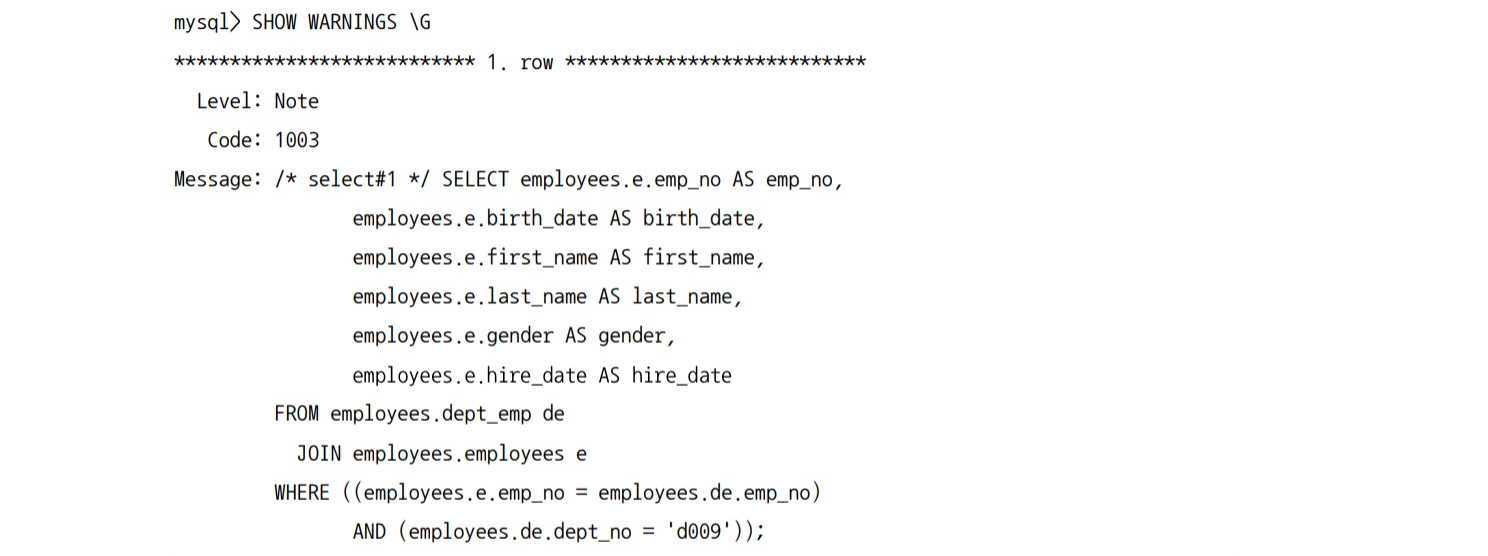
- Table Pullout 최적화는 아래 상황에서 가능함
- 세미 조인 서브쿼리에만 사용 가능
- 서브쿼리 부분이 Unique 인덱스나 Primary Key 룩업으로 결과가 1건인 경우에만 사용 가능
FirstMatch
- First Match 최적화 전략은 IN(subquery) 형태의 세미 조인을 EXISTS(subquery) 형태로 변경하는 최적화 전략
SELECT *
FROM employees e WHERE e.first_name = 'Matt'
AND e.emp_no IN (
SELECT t.emp_no FROM titles t
WHERE t.from_date BETWEEN '1995-01-01' AND '1995-01-30'
);- 위 쿼리👆에서 보면 t.from_date 조건은 해당하는 값 1건만 찾으면 됨
-
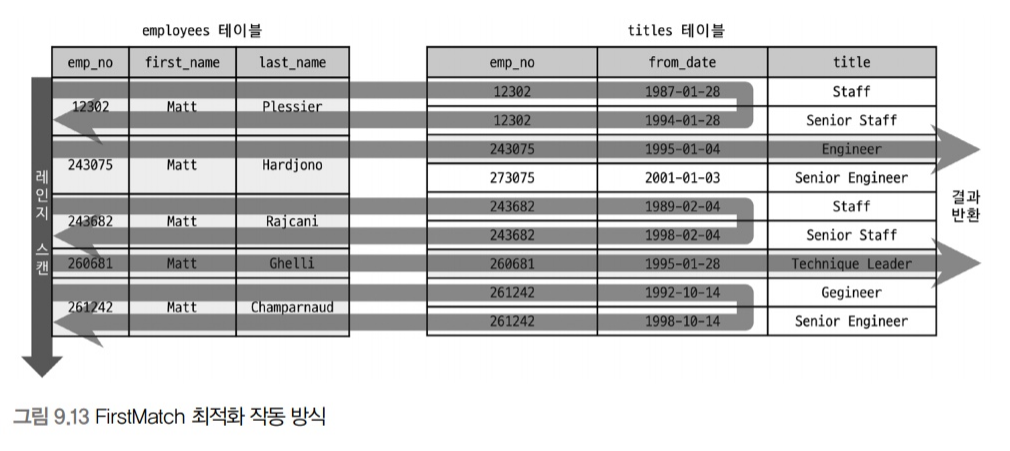
- 12302 사원은 from_date 조건을 만족하는 레코드가 없으므로 결과 반환 X
- 243075 사원은 titles 레코드 중에서 from_date 조건을 만족하는 레코드가 1건 있으므로 더 이상 검색하지 않고 결과 반환
-
- FirstMatch 최적화 특징
- 서브쿼리에서 하나의 레코드만 검색되면 더 이상의 검색을 멈추는 단축 실행 경로이기 때문에 서브쿼리가 참조하는 모든 아우터 테이블이 먼저 조회된 이후에 서브쿼리에서 존재하는지 검증
- FirstMatch 최적화는 GROUP BY나 집합 함수가 사용된 서브쿼리의 최적화에는 사용될 수 없음
LooseScan
-
EXPLAIN SELECT * FROM departments d WHERE d.dept_no IN ( SELECT de.dept_no FROM dept_emp de ); -
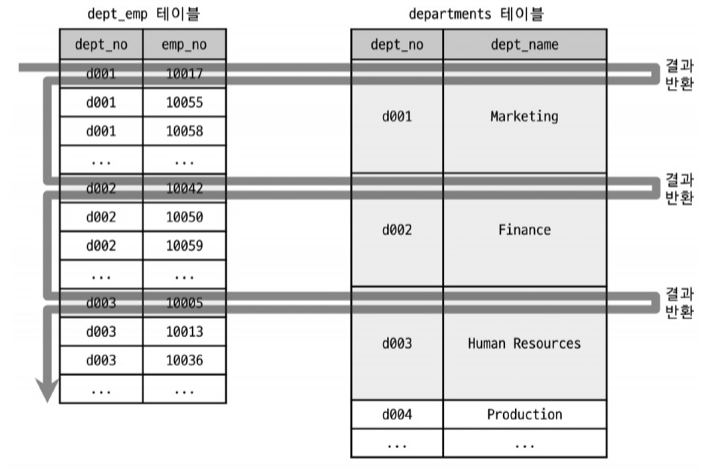
- departments 테이블의 레코드 건수는 9건밖에 안되지만 ㅇept_emp 테이블의 레코드 건수가 33만건이라고 가정
- dept_no만으로 그루핑을 해서 최상단의 것만 가져온다면 결국 9건 밖에 존재하지 않음
Materialization (구체화)
- 세미 조인에 사용된 서브쿼리를 통째로 구체화해서 쿼리를 최적화한다는 의미
- 내부 임시 테이블을 생성한다는 것을 의미
EXPLAIN
SELECT *
FROM employees e
WHERE e.emp_no IN (
SELECT de.emp_no FROM dept_emp de WHERE de.from_date = '1995-01-01'
);위 쿼리는 범위 지정으로 emp_no를 모두 가져와야 하기 때문에 Materialization이 발생한다는 것 같은데, 정확히 이해가 안됨
Duplicate Weedout (중복 제거)
- 세미 조인 서브쿼리를 일반적인 INNER JOIN 쿼리로 바꿔서 실행하고 마지막에 중복된 레코드를 제거하는 방법으로 처리하는 최적화 알고리즘
EXPLAIN
SELECT * FROM employees e
WHERE e.emp_no IN (
SELECT s.emp_no FROM salaries s WHERE s.salary > 150000
)- salaries 테이블의 프라이머리 키가(emp_no + from_date)이므로 salary가 150000 이상인 레코드를 salaries 테이블에서 조회하면 그 결과에는 중복된 emp_no가 발생할 수 있음
condition_fanout_filter (컨디션 팬아웃)
SET optimizer_switch='condition_fanout_filter=on';
SET optimizer_switch='condition_fanout_filter=off';-
--// first_name과 hire_date에 인덱스가 걸려 있음 EXPALIN SELECT * FROM employees e INNER JOIN salaries s ON s.emp_no = e.emp_no WHERE e.first_name = 'Matt' AND e.hire_date BETWEEN '1985-11-21' AND '1986-11-21' - condition_fanout_filter 옵션을 끄면 위 쿼리에서 first_name만을 가지고 예측하지만 옵션을 켜면 hire_date의 분포도까지 고려해서 예측함
- 즉 condition_fanout_filter 옵션은 아래의 경우에 대해서 모든 경우를 예측함
- WHERE 조건절에 사용된 칼럼에 대해 인덱스가 있는 경우
- WHERE 조건절에 사용된 칼럼에 대해 히스토그램이 존재하는 경우
- condition_fanout_filter 옵션을 켤 경우 옵티마이저는 더 많은 시관과 컴퓨팅 자원을 사용함
- 👉 쿼리가 간단하다면 condition_fanout_filter 옵션은 성능 향상에 큰 도움이 되지 않을 수 있음
derived_merge (파생 테이블 머지)
- FROM 절에 사용된 서브쿼리는 먼저 실행해서 그 결과를 임시 테이블로 만든 다음 외부 쿼리 부분을 처리
-
EXPLAIN SELECT * FROM ( SELECT * FROM employees WHERE first_name = 'Matt' ) derived_table WHERE derived_table.hire_date = '1986-04-03'; - MySQL 서버는 내부적으로 임시 테이블을 생성하고 first_name=Matt인 레코드를 employees 테이블에서 읽어서 임시 테이블로 INSERT 함
- 👉 이 때 임시 테이블이 메모리에 다 올라가지 않으면 디스크에 쓰여지게 되는데 이는 많은 오버헤드가 사용될 수 있음
- MySQL 5.7 버전부터는 이렇게 파생 테이블로 만들어지는 서브쿼리를 외부 쿼리와 병합해서 서브쿼리 부분을 제거하는 최적화가 도입됨
- 예를 들면 위 쿼리는 아래와 같이 변경됨
-
mysql> SHOW WARNINGS \G *************************** 1. row *************************** Level: Note Code: 1003 Message: /* select#1 */ SELECT employees.employees.emp_no AS emp_no, employees.employees.birth_date AS birth_date, employees.employees.first_name AS first_name, employees.employees.last_name AS last_name, employees.employees.gender AS gender, employees.employees.hire_date AS hire_date FROM employees.employees WHERE ((employees.employees.hire_date = DATE '1986-04-03') AND (employees.employees.first_name = 'Matt'))
-
- 하지만 다양한 이유로 이렇게 자동으로 병합이 안될 수 있으니 수동으로 작성하는게 좋음
Invisible Index
ALTER TABLE employees ALTER INDEX ix_hiredate INVISIBLE;
--// INVISIBLE로 설정된 인덱스도 사용하게 설정가능
SET optimizer_switch='use_invisible_indexes=on';- INDEX를 지우는게 아니라 INVISIBLE로 설정해서 optimizer가 사용하지 못하게 할 수 있음
- 👉 Index가 생성되긴 함
- INVISIBLE로 설정된 인덱스도 사용하게 설정가능
skip_scan
ALTER TABLE employees
ADD INDEX ix_gender_birthdate (gender, birth_date);
--// 인덱스 안탐
SELECT * FROM employees WHERE birth_date >= '1965-02-01';
--// 인덱스 사용 가능
SELECT * FROM employees WHERE gender = 'M' AND birth_date >= '1965-02-01';- 첫 번째 인덱스 안타는 경우에도 birth_date만 가지고 인덱스를 탈 수 있게 해줌
- 단 선행 테이블의 종류가 다양하면 사용하지 않는 것이 좋음
- skip_scan 설정 방법
-
SET optimizer_switch='skip_scan=on'; --// 특정 테이블에 대해 인덱스 스킵 스캔을 사용하도록 힌트 사용 SELECT /*+ SKIP_SCAN(employees) */ * FROM employees WHERE birth_date >= '1965-02-01';
-
해시 조인
- 해시 조인 쿼리는 최고 스루풋(Best Throughput)에 적합하고 네스티드 루프 조인은 최고 응답 속도(Best Response-time) 전략에 적합
- 해시 조인은 첫 번째 레코드를 찾는데는 시간이 많이 걸리지만 최종 레코드를 찾는 데까지는 시간이 많이 걸리지 않음
- 네스티드 루프 조인은 마지막 레코드를 찾는 데까지는 시간이 많이 걸리지만 첫 번째 레코드를 찾는 것은 상대적으로 빠름
- 대용량 데이터 분석을 위해 MySQL을 사용하지는 않을테니 MySQL 서버가 응답 속도와 스루풋 중 어디에 집중해서 최적화할 것인지 명확해짐
prefer_ordering_index(인덱스 정렬 선호)
EXPLAIN SELECT *
FROM employees
WHERE hire_date BETWEEN '1985-01-01' AND '1985-02-01'
ORDER BY emp_no;- 위 쿼리는 hire_date를 먼저 읽고 emp_no로 정렬을 한 후 반환하거나 emp_no으로 정렬해서 해당 조건에 부합하는지 비교 후 결과를 반환하는 두 가지 실행 계획을 선택할 수 있음
- 그래서 어떤 인덱스가 더 빠른지 미리 알고 있다면 prefer_ordering_index 옵션을 꺼서 내가 지정한 순서대로 인덱스를 사용하도록 할 수 있음
-
SET optimizer_switch='prefer_ordering_index=off'; --// 단일 쿼리에 대해서 prefer_ordering_index를 사용하지 않도록 힌트 사용 SELECT /* SET_VAR(optimizer_switch='prefer_ordering_index=OFF') */ * FROM employees WHERE hire_date BETWEEN '1985-01-01' AND '1985-02-01' ORDER BY emp_no;
-