MySQL
계정
mysql에서는 ip 주소도 계정에 포함이 된다.
예를 들어서 'svc_id'@'192.168.0.10' 이라는 아이디가 있다면 이건 192.168.0.10 ip에서만 접속이 가능하다. 만약 외부의 모든 pc에서 접속이 가능하도록 하고 싶다면 'svc_id'@'%'와 같은 형식으로 % 기호를 사용하면 된다.
만약에 'svc_id'@'192.168.0.10'(비밀번호123)라는 계정과 'svc_id'@'%'라는 계정이 있다고 가정할 때 MySQL은 범위가 작은 계정부터 선택을 한다.
즉, 192.168.0.10 pc에서 비밀번호 123으로 MySQL 서버에 접근하게 되면 접근에 실패하게 된다.
MySQL 8.0
MySQL 8.0 부터 시스템 계정과 일반 계정으로 나뉜다.
- 시스템 계정 : 계정 관리, 세션 관리, 스토어드 프로그램 사용시 DEFINER를 타 사용자로 지정
mysql에서는 특별한 역할을 담당하는 계정이 존재한다. 기본적으로 잠겨있기 때문에 보안을 걱정하지 않아도 된다. - 'mysql.sys'@'localhost' : 기본적으로 내장된 sys 스키마의 객체(뷰나 함수, 그리고 프로시저)들의 DFINER로 사용되는 계정 - 'mysql.session'@'localhost' : MySQL 플러그인이 서버로 접근할 때 사용되는 계정
- 'mysql.infoschema'@'localhost' : information_schema에 정의된 뷰의 DEFINER로 사용되는 계정
아키텍쳐
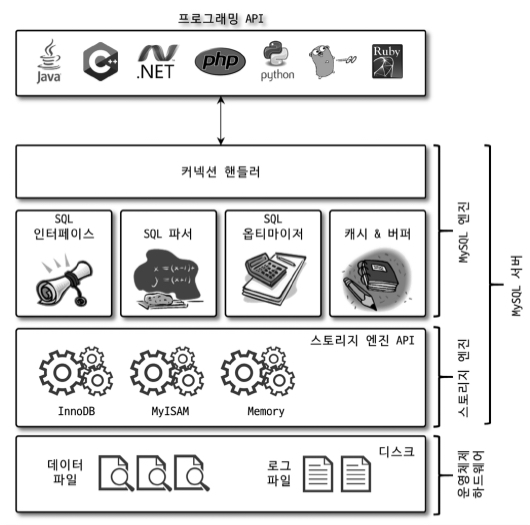
- MySQL 엔진 : 클라이언트로부터의 접속 및 쿼리 요청을 처리하는 커넥션 핸들러, SQL 파서 및 전처리기, 옵티마이저가 중심을 이룬다.
- 스토리지 엔진 : SQL 문장을 분석하거나 최적화하는 등 DBMS의 두뇌에 해당하는 처리를 수행하고 실제 데이터를 디스크 스토리지에 저장하거나 디스크 스토리지로부터 데이터를 읽어오는 부분을 담당한다.
핸들러 API
MySQL 엔진의 쿼리 실행기에서 데이터를 쓰거나 읽어야 할 때는 각 스토리지 엔진에 쓰기 또는 읽기를 요청하는데 이러한 요청을 핸들러(Handler) 요청이라고 하고, 여기서 사용되는 API를 핸들러 API라고 한다.
SHOW GLOBAL STATUS LIKE 'Handler조%';핸들러라는 단어는 MySQL 서버의 소스코드로부터 넘어온 표현인데, 사람이 핸들을
이용해서 자동차를 운전하듯이, 프로그래밍언어에서 어떤 기능을 호출하기 위해 사용하는 운전대와 같은 역할을 하는 객체를 핸들러라고 한다. MySQL 엔진이 각
스토리지 엔진에게 명령하려면 반드시 핸들러를 통해야만 한다.
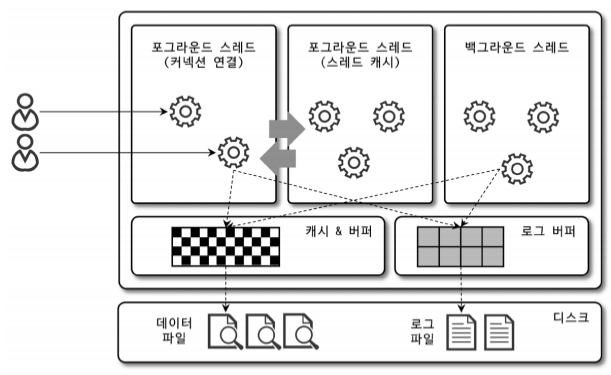
MySQL 스레딩 구조
SELECT thread_id, name, type, processlist_user, processlist_host
FROM performance_schema.threads ORDER BY type, thread_id;- 포그라운드 스레드(사용자 스레드)
- 클라이언트 하나당 하나의 스레드를 형성한다.
- 읽기 작업을 주로 담당한다.
- 백그라운드 스레드 : MyISAM의 경우에는 별로 해당사항이 없는 부분이지만 InnoDB는 다음과 같은 작업이 백그라운드로 처리된다.
- 인서트 버퍼를 병합하는 스레드
로그를 디스크로 기록하는 스레드InnoDB 버퍼 풀의 데이터를 디스크에 기록하는 스레드- 데이터를 버퍼로 읽어오는 스레드
- 잠금이나 데드락을 모니터링하는 스레드
InnoDB에서는 쓰기 작업을 백그라운드에서 처리해서 지연이 없다.
하지만 MyISAM에서는 쓰기 작업과 읽기 작업을 모두 사용자 스레드에서 처리하기 때문에 대기 시간이 발생할 수 있다.
쓰기 스레드의 경우는 아주 많은 작업을 백그라운드로 처리하기 때문에 일반적인 내장 디스크를 사용할 때는 2~4정도로 넉넉하게 설정하는게 좋다.
InnoDB와 MyISAM의 차이
- InnoDB : 쓰기 작업을 버퍼링해서 일괄 처리하는 기능이 탭재되있다.
- MyISAM : 사용자가 스레드(포그라운드 스레드)가 쓰기 작업까지 함께 처리하도록 설계돼 있다. => 쓰기 작업이 끝날 때까지 기다려야 한다.
메모리 할당 및 사용 구조
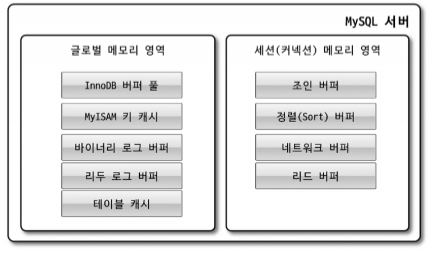
- 글로벌 메모리 : MySQL 서버가 시작될 때 운영체제로부터 할당된다.
- 로컬 메모리 영역 : 세션 메모리 영역이라고도 표현하고 MySQL 서버상에 존재하는 클라이언트 스레드가
쿼리를 처리하는데 사용하는 메모리 영역이다.
플러그인 스토리지 엔진 모델
DBMS의 전체 기능이 아닌 일부분의 기능만 수행하는 엔진을 말한다.
SHOW ENGINE;SHOW PLUGINS;GROUP BY나 ORDER BY 등의 복잡한 처리는 스토리지 엔진 영역이 아니라 MySQL 처리
영역인 쿼리 실행기에서 처리된다.
컴포넌트
MySQL 8.0부터는 기존의 플러그인 아키텍처를 대체하기 위해 컴포넌트 아키텍처가 지원된다. 이는 다음과 같은 점들은 보완하기 위한 것이다.
- 플러그인끼리 통신 불가
- 서버의 변수나 함수를 직접 호출하기 때문에 안전하지 않음(캡슐화)
- 플러그인은 상호 의존 관계를 설정할 수 없음
-- 컴포넌트 설치
install component 'file://component_validate_password';
-- 설치된 컴포넌트 확인
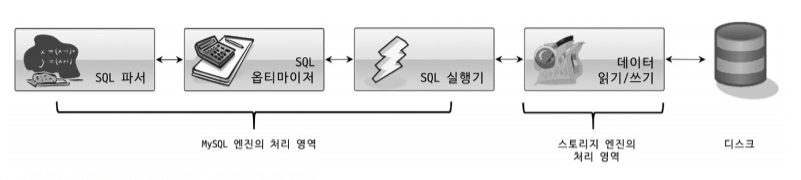
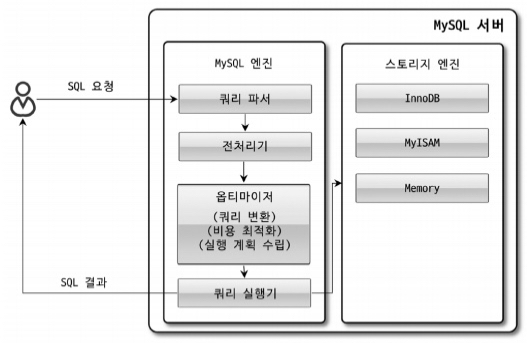
SELECT * FROM mysql.component;쿼리 실행 구조
-
쿼리 파서 : 사용자 요청으로 들어온 쿼리문장을
토큰(MySQL이 인식할 수 있는 최소 단위의 어휘나 기호)으로 분리해 트리 형태의 구조로 만들어 내는 작업을 의미한다.기본 문법오류가 이 과정에 의해서 발견된다. -
전처리기 : 문장에 구조적인 문제점이 있는지 확인한다. 각 토큰을 테이블 이름이나 칼럼 이름, 또는
내장 함수와 같은 개체를 매핑해 해당 객체의 존재 여부와 객체의 접근 권한 등을 확인한다. -
옵티마이저 : 사용자의 요청으로 들어온 쿼리 문장을 저렴한 비용으로 가장 빠르게 처리할지를 결정하는 역할을 담당한다. DMBS의 두뇌에 해당하는 부분.
-
실행 엔진 : 실행 엔진과 핸들러는 손과 발에 비유할 수 있다. 예를 들자면,
- 실행 엔진이 핸들러에게 임시 테이블을 만들라고 요청
- 다시 실행 엔진은 WHERE 절에 일치하는 레코드를 읽어오라고 핸들러에게 요청
- 읽어온 레코드들을 1번에서 준비한 임시 테이블로 저장하라고 핸들러에게 요청
- 데이터가 준비된 임시 테이블에서 필요한 방식으로 데이터를 읽어 오라고 핸들러에게 다시 요청
- 최종적으로 실행 엔진은 결과를 사용자나 다른 모듈로 넘김
-
핸들러(스토리지 엔진) : MySQL 서버의 가장 밑단에서
실행 엔진의 요청에 따라 데이터를 디스크로 저장하고 읽어오는 역할을 담당한다. -
복제 :
-
쿼리 캐시 : SQL 실행 결과를 메모리에 캐시한다.
성능 문제로 인해서 8.0에서 완전히 삭제되었다. -
스레드 풀 : 엔터프라이즈에서 제공하는 기능. 내부적으로 사용자의 요청을 처리하는 스레드 개수를 줄여서 동시 처리되는 요청이 많아도 제한된 개수의 스레드 처리에만 집중할 수 있게 해서 서버의 자원 소모를 줄이는 것이 목적이다.
InnoDB 엔진 아키텍처

InnoDB의 모든 테이블은 기본적으로 프라이머리 키를 기준으로 클러스터링되어 저장된다.(프라이머리 키를 기준으로 순서가 정해진다.)
InnoDB 버퍼 풀
InnoDB에서 가장 핵심적인 부분으로 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간이다.
일반적으로 운영체제의 메모리 공간이 8GB 미만이라면 전체의 50%정도 50GB 이상이라면 대략 15GB에서 30GB 정도를 운영체제와 다른 응용 프로그램을 위해서 남겨두고 나머지를 InnoDB 버퍼 풀로 할당하는게 좋다.
InnoDB 데이터 찾는 순서
- 필요한 레코드가 저장된 데이터 페이지가 버퍼 풀에 있는지 검사 A. InnoDB 어댑티브 해시 인덱스를 이용해 페이지를 검색 B. 해당 테이블의 인덱스(B-Tree)를 이용해 버퍼 풀에서 페이지를 검색 C. 버퍼 풀에 이미 데이터 페이지가 있었다면 해당 페이지의 포인터를 MRU 방향으로 승급
- 디스크에서 필요한 데이터 페이지를 버퍼 풀에 적재하고, 적재된 페이지에 대한 포인터를 LRU 헤더 부분에 추가
- 버퍼 풀의 LRU 헤더 부분에 적재된 데이터 페이지가 실제로 읽히면 MRU 헤더 부분으로 이동(Read Ahead와 같이 대량 읽기의 경우 버퍼 풀로 적재는되고 실제 쿼리에서 사용되지 않을 수도 있으며, 이 경우 MRU로 이동하지 않음)
- 버퍼 풀에 상주하는 데이터 페이지는 사용자 쿼리가
얼마나 최근에 접했었는지에 따라 나이(Age)가 부여되며, 버퍼 풀에 상주하는 동안 쿼리에서 오랫동안 사용되지 않으면 데이터 페이지에 부여된 나이가 오래되고 결국 해당 페이지는 버퍼 풀에서 제거된다. - 필요한 데이터가 자주 접근됐다면 해당 페이지의 인덱스 키를
어댑티브 해시 인덱스에 추가
LRU : Least Recently Used MRU : Most Recently Used
버퍼 풀과 리두 로그
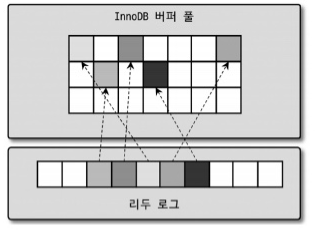
InnoDB의 버퍼 풀은 디스크에서 읽은 상태로 전혀 변경되지 않은 클린 페이지(Clean Page)와 함께 INSERT, UPDATE, DELETE 등의 명령으로 변경된 데이터를 가진 더티 페이지(Dirty Page)로 구분된다.
더티 페이지는 데이터 상태가 다르기 때문에 언젠가는 디스크로 기록돼야 한다.
InnoDB 스토리지 엔진에서 리두 로그는 1개 이상의 고정 크기 파일을 연결해서 순환 고리처럼 사용한다.
즉, 데이터 변경이 계속 발생하면 리두 로그 파일에 기록됐던 로그 엔트리는 어느 순간 다시 새로운 로그 엔트리로 덮어 쓰인다.
그래서 InnoDB 스토리지 엔진은 전체 리두 로그 파일에서 재사용 가능한 공간과 당장 재소용 불가능한 공간을 구분해서 관리해야 하는데, 재사용 불가능한 공간을 활성 리두 로그(Active Redo Log)라고 한다.
리두로그 : 데이터베이스에 저장된 값 또는 데이터베이스 구조에 변경사항이 생기는 경우 이러한 정보를 놓치지 않고 저장하는 메모리 영역
MySQL Lock 동작방식
Next key Lock
넥스트 키 락(Next-Key Lock)
넥스트 키 락은 인덱스 레코드에 대한 레코드 락과 인덱스 레코드 이전의 갭에 대한 갭 락이 결합된 형태의 락입니다.
InnoDB는 테이블 인덱스를 검색하거나 스캔할 때, 해당 인덱스 레코드에 공유 락(Shared Lock) 또는 배타적 락(Exclusive Lock)을 설정하여 **레코드 단위의 락을 구현합니다.
** 즉, 행 레벨 락(row-level lock)은 실제로는 인덱스 레코드에 대한 락인 셈입니다.
넥스트 키 락은 인덱스 레코드에 대한 락과 해당 인덱스 레코드 이전의 갭에 대한 갭 락이 결합된 락입니다.
예를 들어, 하나의 세션이 인덱스에 있는 레코드 R에 대해 공유 락 또는 배타적 락을 가지고 있다면, 다른 세션은 인덱스 순서에서 R 바로 앞의 갭에 새로운 인덱스 레코드를 삽입할 수 없습니다.
예시
다음과 같이 인덱스에 10, 11, 13, 20이라는 값이 있다고 가정해 봅시다.
이 인덱스에 대해 생성될 수 있는 넥스트 키 락의 간격은 다음과 같습니다.
여기서 소괄호 ( )는 경계값을 제외하며, 대괄호 [ ]는 경계값을 포함함을 의미합니다.
- (-∞, 10] : 10까지 포함하는 락 범위
- (10, 11] : 10과 11 사이의 갭과 11을 포함하는 락 범위
- (11, 13] : 11과 13 사이의 갭과 13을 포함하는 락 범위
- (13, 20] : 13과 20 사이의 갭과 20을 포함하는 락 범위
- (20, +∞) : 20 이후의 갭을 락으로 설정. Supremum(수프리멈) 레코드가 포함됨
🔎 Supremum(수프리멈)이란?
Supremum은 인덱스에 존재하지 않는 가상의 레코드로, 가장 큰 인덱스 값보다 큰 값을 나타냅니다.
따라서(20, +∞)에 대한 넥스트 키 락은 실제로 가장 큰 인덱스 값(20) 이후의 갭만을 락으로 설정하게 됩니다. Supremum은 가상의 레코드이기 때문에, 실제 인덱스 레코드는 아닙니다.
트랜잭션 격리 수준과 넥스트 키 락의 관계
InnoDB는 기본적으로 REPEATABLE READ (반복 가능한 읽기) 격리 수준으로 동작합니다.
이 격리 수준에서는 InnoDB가 **검색(search) 및 인덱스 스캔(scan)**을 수행할 때 넥스트 키 락(Next-Key Lock)을 사용합니다.
이로 인해, 트랜잭션이 실행되는 동안 **팬텀 레코드(Phantom Row)**가 발생하는 것을 방지할 수 있습니다.
Next Key Lock vs Table Lock
-
Next-Key Lock (인덱스 기반 잠금) 작동 방식: 검색 범위의 인덱스 레코드와 그 앞의 갭(공백)까지 잠금.
예를 들어, SELECT * FROM users WHERE age BETWEEN 10 AND 20 FOR UPDATE;를 실행하면, 인덱스 10 ≤ age ≤ 20에 포함되는 인덱스 레코드뿐만 아니라, age = 10 이전의 갭과 age = 20 이후의 갭까지도 잠기게 됩니다.
→ 따라서, 특정 인덱스 구간에만 제한적으로 락이 걸립니다. -
Table Lock (테이블 전체 잠금) 작동 방식: 테이블 전체에 대해 읽기/쓰기 작업을 모두 잠금.
특정 트랜잭션이 테이블에 대해 LOCK TABLES 명령이나 DDL(ALTER, DROP) 명령을 수행하면, 해당 테이블에 대해 다른 세션의 읽기/쓰기 작업이 모두 차단됩니다.
Next-Key Lock이 Table Lock과 같아지는 경우
- 인덱스를 사용하지 않는 경우
- 쿼리에서 FULL TABLE SCAN이 발생하면, 넥스트 키 락이 인덱스를 통한 범위가 아니라 테이블 전체에 걸립니다.
- 예: SELECT * FROM users WHERE name = 'John' FOR UPDATE; (name에 인덱스가 없는 경우)
- WHERE 조건 없이 검색하는 경우
- 예: SELECT * FROM users FOR UPDATE;
- WHERE 조건이 없기 때문에, 모든 레코드에 넥스트 키 락이 걸리고, 사실상 Table Lock과 동일한 효과를 냅니다.
- 인덱스를 타지 않고 Primary Key를 락하는 경우
- 예: SELECT * FROM users WHERE id > 0 FOR UPDATE; (id에 인덱스가 있더라도 WHERE 조건이 광범위한 경우)
- 넥스트 키 락이 인덱스 범위 전체에 걸리면서, 전체 테이블에 락이 걸릴 수 있습니다.
Gap Lock
- **갭 락(Gap Lock)**은 **인덱스 레코드 사이의 공백(Gap)**에 대해 잠금을 거는 메커니즘입니다.
- 목적: 다른 트랜잭션이 이 갭에 새로운 레코드를 삽입하지 못하게 방지하는 것.
- 적용 범위: 인덱스의 이전 레코드와 다음 레코드 사이의 간격 또는 첫 번째 레코드의 앞쪽 간격과 마지막 레코드의 뒤쪽 간격까지 포함합니다.
Gap Lock 동작 원리
- REPEATABLE READ 이상의 트랜잭션 격리 수준에서만 동작합니다.
- READ COMMITTED 격리 수준에서는 갭 락이 비활성화됩니다.
- 팬텀 레코드(Phantom Row) 삽입을 방지하기 위해 필요합니다.
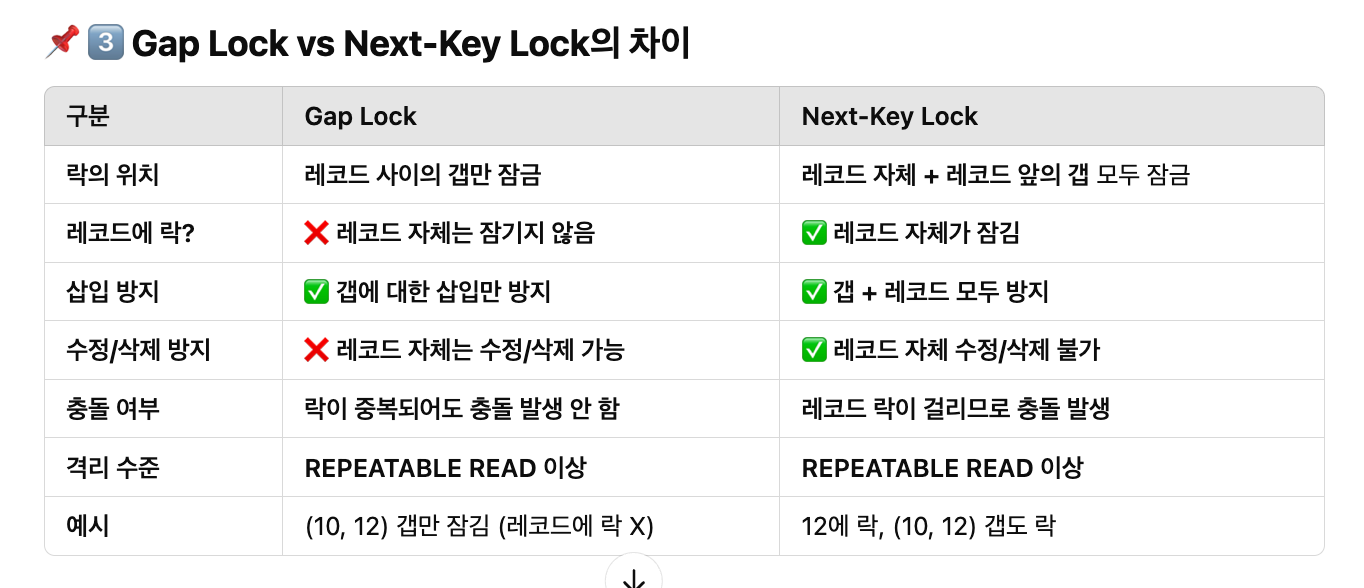
Gap Lock과 Next Key Lock의 차이
- Gap Lock이란?
- 정의: 인덱스 레코드 사이의 공백(Gap)에 걸리는 락
- 목적: 다른 트랜잭션이 갭에 새 레코드를 삽입하지 못하도록 방지
- 락 범위: 레코드 사이의 공백(즉, 레코드 자체는 락이 걸리지 않음)
- Next-Key Lock이란?
- 정의: Gap Lock + Record Lock(레코드 자체에 락) = Next-Key Lock
- 목적: 다른 트랜잭션이 레코드 자체의 수정/삭제 + 갭에 새로운 레코드 삽입을 방지
- 락 범위: 레코드 자체 + 그 앞의 갭이 모두 잠김
Reference
MySQL Client
Ubuntu
command line에서 mysql client를 설치하고 접속하는 방법이다.
sudo apt-get -y install mysql-client
mysql -u [유저명] -p -h 호스트 주소