SQL의 종류
MariaDB, MySQL, Oracle, MS-SQL, PostgreSQL, SQLite 등은 모두 동일한 SQL문으로 동작한다.
SQL에서 사용되는 명칭(호칭)
| 파일시스템 | DB 모델링 | RDB | |
|---|---|---|---|
| 데이터가 담기는 영역 | 파일(File) | 엔티티(Entity) | 테이블(Table) |
| 한 줄(하나의 데이터 뭉태기) | 레코드(Record) | 튜플(Tuple) | 행(Row) |
| 한 줄의 데이터의 유니크한 값 | 키(Key) | 유니크값(Identifier) | 키(Primary Key), (Unique Key) |
| 한 줄의 각 칸에 대한 속성값 | 필드(Field) | 속성(Attribute) | 열(Column) |
Data Definition Languege (DDL)
데이터를 정의할 때 쓴다.
- CREATE : 테이블의 생성
- ALTER : 테이블의 구조를 변경
- DROP : 테이블 삭제
- RENAME : 테이블 이름 변경
- COMMENT : 테이블에 대한 설명
- TRUNCATE : 데이터 초기화
CREATE
CREATE DATABASE DB_NAME;-- Default 부터는 줘도 되고 안줘도 됨
-- PRIMARY KEY는 기본이 되는 컬럼이 어딘지 지정해줌(ID를 담고 있는 컬럼)
CREATE TABLE TABLE_NAME (
[컬럼이름] [데이터 타입] [속성] [기본값] [코멘트],
[컬럼이름] [데이터 타입] [속성] [기본값] [코멘트],
[컬럼이름] [데이터 타입] [속성] [기본값] [코멘트],
...
PRIMARY KEY (컬럼이름)
);에시
CREATE DATABASE user;CREATE TABLE `user` (
`id` bigint(32) NOT NULL AUTO_INCREMENT COMMENT 'index',
`name` varchar(50) NOT NULL COMMENT '사용자이름',
`age` INT NULL DEFAULT '1' COMMENT '사용자나이',
`email` varchar(100) NULL DEFAULT '' COMMENT '이메일 주소',
PRIMARY KEY(`id`)
);ALTER
테이블의 구조를 변경할 때 사용한다. 예를 들면 아래 sql 쿼리는 store_menu라는 테이블에 idx_store_id라는 인덱스를 추가하는데 idx_store_id는 store_id라는 컬럼을 기준으로 정렬을 하겠다는 의미이며, visible이라는 옵션은 인덱스를 보이게 할 것인지 안보이게 할 것인지를 결정한다.
ALTER TABLE delivery.store_menu
add INDEX idx_store_id (store_id ASC) visible;컬럼이름 변경
ALTER TABLE store
CHANGE thumbnail_url thumbnail_url VARCHAR(500) Not Null;컬럼 연관관계(fk) 설정
아래 쿼리는 fk_store_user_order_id라는 Key를 갖고 user_order_id의 지역키 store_id와 store 테이블의 id를 연결시키는 것이다.
결론적으로 아래 쿼리를 통해서 user_order_id (n:1) store의 관계가 만들어진다.
ALTER TABLE delivery.user_order_id
ADD CONSTRAINT fk_store_user_order_id
FOREIGN KEY (store_id)
REFERENCES delivery.store (id);TRUNCATE
TRUNCATE [테이블 명]예시
TRUNCATE `user`.`user`DROP
DROP TABLE [테이블명]Data Manipulation Language (DML)
데이터를 조작할 때 쓴다.
- SELET : 데이터 조회
- INSERT : 데이터 삽입
- UPDATE : 데이터 수정
- DELETE : 데이터 삭제
- JOIN : 테이블을 합칠 때 사용
JOIN
만약에 user 1의 주문번호 1번을 찾는다고 가정하자, user 1의 이름과 주문한 상품의 이름을 알고 싶은데
테이블이
user < 1:N > user_order_id < 1:N > user_order_menu < 1:N > store_menu
와 같은 형식으로 구성되어 있다고 가정할 때
평문으로 하나하나 조회를 한다면
아래 쿼리를 통해서 user name을 조회하고
select u.name from user as u where u.id = 1;user가 주문한 주문번호를 조회하고
select * from user_order_id as uoi where uoi.user_id = 1;user_order_menu를 조회하고
select uom.store_menu_id from user_order_menu as uom where uom.user_order_id = 1;그 메뉴를 store_menu에서 찾아내서
select sm.name from store_menu as sm where sm.id = 1 or sm.id = 2;사용자에게 출력해줘야 한다.
- on : 조인의 관계를 지정한다. 예를 들어서 user.id와 user_order_id.user_id를 조인한다고 가정하면
on user.id = user_order_id.user_id와 같이 사용한다.
내부조인
가장 많이 쓰이는 조인으로 그냥 조인이라고 표현하면 이는 내부조인을 뜻하는 것이다.
일대다 연결에 주로 사용되며 기본형태는
select [컬럼목록]
from [첫 번째 테이블]
inner join [두 번째 테이블] on [조인조건]
where [검색조건]과 같다.
외부조인
LEFT OUTER JOIN

RIGHT OUTER JOIN
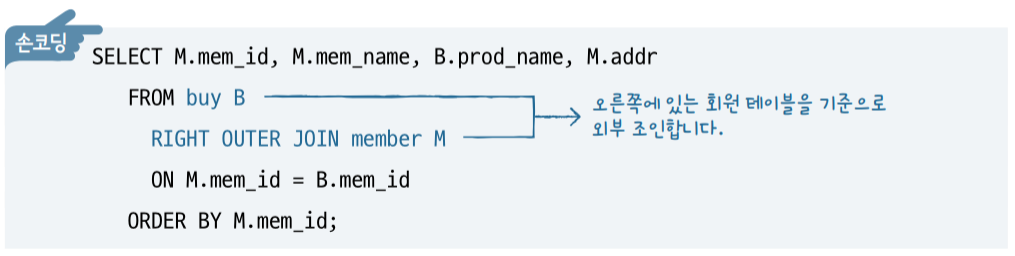
FULL OUTER JOIN
왼쪽이든 오른쪽이든 한 쪽에 들어 있는 내용이면 모두 출력한다.
상호조인
상호조인은 모든 행에 대해서 조인을 랜덤하게 수행하는 것으로 만약에 A 테이블에 10행, B 테이블에 10행이 있다면 10 * 10 = 100개의 행이 생성된다.
주로 테스트 용도로 많이 사용한다.
use market_db;
select *
from buy cross join member;자체조인
자체조인은 자기자신과 조인을 한다는 의미인데, 예를 들자면
USE market_db;
CREATE TABLE emp_table (emp CHAR(4), manager CHAR(4), phone VARCHAR(8));
INSERT INTO emp_table VALUES('대표', NULL, '0000');
INSERT INTO emp_table VALUES('영업이사', '대표', '1111');
INSERT INTO emp_table VALUES('관리이사', '대표', '2222');
INSERT INTO emp_table VALUES('정보이사', '대표', '3333');
INSERT INTO emp_table VALUES('영업과장', '영업이사', '1111-1');
INSERT INTO emp_table VALUES('경리부장', '관리이사', '2222-1');
INSERT INTO emp_table VALUES('인사부장', '관리이사', '2222-2');
INSERT INTO emp_table VALUES('개발팀장', '정보이사', '3333-1');
INSERT INTO emp_table VALUES('개발주임', '정보이사', '3333-1-1');이러한 테이블이 있다고 가정할 때
use market_db;
select A.emp '직원', B.emp '직송상관', B.phone '직속상관연락처'
from emp_table A
inner join emp_table B on A.manager = B.emp;이런 식으로 테이블 내에서 관계를 표현할 수 있다.
이를 통해서 '경리부장'의 직속상관을 알고 싶을 때 아래와 같이 활용할 수 있다.
use market_db;
select A.emp '직원', B.emp '직송상관', B.phone '직속상관연락처'
from emp_table A
inner join emp_table B on A.manager = B.emp
where A.emp = '경리부장';별칭지정
컬럼에 별칭을 지정하게 되면 반드시 별칭을 사용해야 한다.
select b.mem_id, m.mem_name, b.prod_name, m.addr, concat(m.phone1, m.phone2) '연락처'
from buy as b
inner join member as m
on b.mem_id = m.mem_id;UPDATE
UPDATE [테이블 이름] SET
[컬럼이름] = [값]
WHERE [조건절]예시
UPDATE user.user SET
age = 30
WHERE name = '한국사랑'SELECT
SELECT [선택할 필드]
FROM [테이블 명] AS [별칭]
WHERE [조건절]ORDER BY
ORDER BY절은 정렬을 할 때 사용한다.
- ASC : 오름차순 정렬
- DESC : 내림차순 정렬
create table SQLD.member (
GRADE varchar(50),
NAME varchar(100),
MEMBER_NO BIGINT(50)
);
insert into SQLD.member (GRADE, NAME, MEMBER_NO) values ('3등급', '남길동', 5);
insert into SQLD.member (GRADE, NAME, MEMBER_NO) values ('4등급', '북길동', 6);
insert into SQLD.member (GRADE, NAME, MEMBER_NO) values ('2등급', '홍길동', 2);
insert into SQLD.member (GRADE, NAME, MEMBER_NO) values ('2등급', '서길동', 1);
insert into SQLD.member (GRADE, NAME, MEMBER_NO) values ('1등급', '동길동', 3);
# 1 ~ 4 등급까지 정렬
select GRADE, NAME, MEMBER_NO from SQLD.member ORDER BY GRADE ASC, MEMBER_NO;
# 1 ~ 4 등급까지 정렬하고 같은 등급은 MEMBER_NO 내림차순으로 정렬
select GRADE, NAME, MEMBER_NO from SQLD.member ORDER BY GRADE ASC, MEMBER_NO DESC;LIMIT
limit [숫자]를 통해서 조회할 데이터의 개수를 제한할 수 있다.
# 3개
select mem_name, height from market_db.member order by height desc limit 3;
# 3위부터 2개
select mem_name, height from market_db.member order by height desc limit 3, 2;GROUP BY
Group by는 말 그대로 데이터를 그룹별로 묶을 수 있도록 해주는 절이다.
예를 들어서 mem_id가 같은 그룹에 대해서 amount의 합을 구해주고 싶다면 아래와 같이 사용할 수 있다.
select mem_id, sum(amount) from market_db.buy group by mem_id;
select mem_id '회원 아이디', sum(price*amount) '총 구매 개수' from market_db.buy group by mem_id;집계 함수
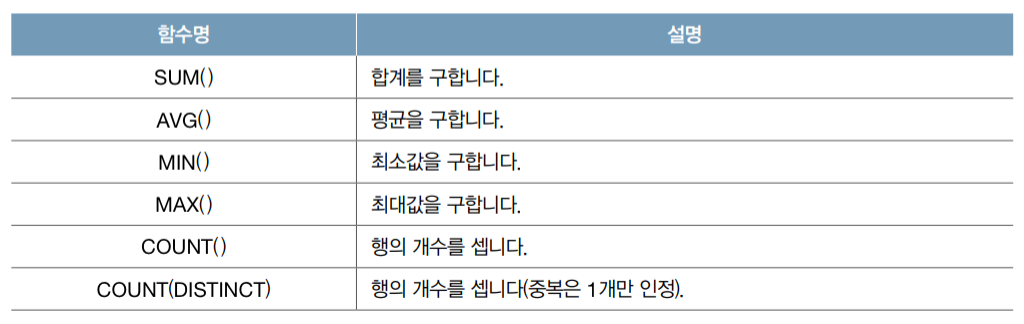
select AVG(col1) as result1, SUM(col2) as result2, count(col3) as result3 from SQLD.sample;HAVING
HAVING은 Group By절을 사용할 때 where 절처럼 사용하는 조건이라고 생각하면 되는데 주로 데이터를 그루핑 할 때 HAVING 뒤에 나오는 조건이 그룹에 포함되느냐/마느냐를 결정한다.

DISTINCT
select 문을 사용할 때 컬럼앞에 DISTINCT를 붙여주면 중복된 데이터를 제거하고 조회할 수 있다.
# addr에서 중복 제거
select distinct addr from market_db.member order by addr;INSERT
INSERT INTO [테이블 이름] (
[컬럼이름1],
[컬럼이름1],
[컬럼이름3]
)
VALUES(
[컬럼1의 데이터 값],
[컬럼2의 데이터 값],
[컬럼3의 데이터 값],
)예시
INSERT INTO `user`.`user`
(
`name`,
`age`,
`email`
)
VALUES
(
'홍길동',
10,
'rookedsysc36@gmail.com'
) DELETE
DELETE FROM [테이블 명] WHERE [조건절]예시
DELETE FROM `user`.`user`
WHERE name = '한국사랑'SELECT * FROM book_store.`user` WHERE score > 95;Data Control Launguage (DCL)
데이터를 제어하는데 사용한다. 여기에서 COMMIT과 ROLLBACK은 Spring의 트랜잭션이 관리한다.
- GRANT : 사용자에게 권한을 부여
- REVOKE : 사용자의 권한을 제거
- COMMIT : 트랜잭션의 작업이 정상적으로 완료
- ROLLBACK : 트랜잭션의 작업이 비정상적으로 종료되어 원래 상태로 복구
Data Type
필수로 기억해야할거
| 데이터 타입 | Java | 설명 |
|---|---|---|
| VARCHAR(N) | String | 가변 길이 문자열 |
| TEXT(N) | String | 문자열 데이터(최대 65,535자) |
| JSON | String | JSON 문자열 데이터 |
| INT | Integer, int | 정수형 데이터 |
| BIGINT | Long, long | 정수형 데이터(무제한 수 표현), primary key 잡을 때 사용 |
| DATE | Date, LocalDate | 날짜 데이터 |
| TIME | Time, LocalTime | 시간형태 데이터 |
| TIMESTAMP | DateTime, LocalDateTime | 날짜와 시간 데이터, Time Zone의 속성을 사용 |
문자타입
| 데이터 타입 | Java | 설명 |
|---|---|---|
| CHAR(N) | String | 고정 길이 문자열 |
| VARCHAR(N) | String | 가변 길이 문자열 |
| TINYTEXT(N) | String | 최대 255자의 가변 길이 문자열 |
| TEXT(N) | String | 최대 65,535자의 가변 길이 문자열 |
| MEDIUMTEXT(N) | String | 최대 16,777,215자의 가변 길이 문자열 |
| LONGTEXT(N) | String | 최대 4,294,967,295자의 가변 길이 문자열 |
| JSON | String | JSON 문자열 데이터 |
숫자타입
Java에서 사용하는 데이터 타입일 때는 프리미티브 타입을 사용하지 말고 레퍼런스 타입을 사용하면 된다.
| 데이터 타입 | Java | 설명 |
|---|---|---|
| TINYINT(N) | Integer, int | 정수형 데이터 -128 ~ +127, 0 ~ 255 |
| SMALLINT | Integer, int | 정수형 데이터 -32768 ~ +32767, 0 ~ 65535 |
| MEDIUMINT | Integer, int | 정수형 데이터 -8388608 ~ +8388607, 0 ~ 16777215 |
| INT | Integer, int | 정수형 데이터 -2147483648 ~ +2147483647, 0 ~ 4294967295 |
| BIGINT | Long, long | 정수형 데이터 (무제한 수 표현) |
| FLOAT | Float, float | 부동 소수점 데이터 |
| DECIMAL | BigDecimal | 고정 소수점 데이터(금액 계산시 사용) |
| DOUBLE | Double, double | 부동 소수점 데이터 |
시간
| 데이터 타입 | Java | 설명 |
|---|---|---|
| DATE | java.util.Date, java.sql.Date | 날짜 데이터 |
| TIME | java.util.Date, java.sql.Date | 시간 데이터 |
| DATETIME | java.util.Date, LocalDateTime | 날짜와 시간 데이터 |
| TIMESTAMP | java.util.Date, LocalDateTime | 날짜와 시간 데이터, Time Zone의 속성을 사용 |
| YEAR | Year | 년도 데이터 |
Byte 형태
| 데이터 타입 | Java | 설명 |
|---|---|---|
| BINARY(N) | byte[] | 이진 데이터 |
| BYTE(N) | byte[] | CHAR 형태의 이진 타입 |
| VARBINARY(N) | byte[] | 가변 길이(VARCHAR) 이진 데이터 |
VIEW
뷰(view)는 테이블과 상당히 유사한 성격의 데이터베이스 개체이다.
일종의 가상의 테이블이라고 할 수 있는데, 진짜 테이블에 Link된 개념이라고 볼 수 있다.
VIEW를 사용하는 이유로는 크게 2가지를 두는데
- 보안에 도움이 된다.
- 긴 SQL 문을 간략하게 만들 수 있다.
는 장점이 있다. 내 생각에는 보여주고 싶은 부분만 보여줄 수 있다는데서 오는 장점인 것 같다.
바로 가기 아이콘과 유사한 개념이라고 할 수 있다.
👇 이렇게 생성된 view는 일반 테이블처럼 접근할 수 있다.
create view member_view as
select *
from shop_db.member;스토어드 프로시저
SQL에서 제공하는 프로그래밍 기능으로 여러 개의 SQL 문을 하나로 묶어서 편리하게 사용할 수 있게 해주는 기능이다.
DELIMITER// ~ DELIMITER안에 BEGIN ~ END을 넣어주고 BEGIN ~ END 사이에 SQL문을 넣어주면 된다.
delimiter //
create procedure myProc()
BEGIN
select * from shop_db.member where member_name = '나훈아';
select * from shop_db.product where product_name = '삼각김밥';
end //
delimiter ;이를 실행하기 위해서는 CALL 키워드를 사용해서 프로시저의 이름을 지정해주면 된다.
call myProc();IF문
IF문은 기본적으로
IF <조건식> THEN
BEGIN
SQL 문장들
END IF;
END$$와 같은 형태를 띈다. 👇는 예시코드.
drop procedure if exists ifProc1;
DELIMITER $$
CREATE PROCEDURE ifProc1()
BEGIN
IF 100 = 100 THEN
SELECT '100 = 100' AS RESULT;
ELSE
SELECT '100 != 100' AS RESULT;
END IF;
END$$
DELIMITER ;
CALL ifProc1();활용예시 2
DROP PROCEDURE IF EXISTS ifProc3;
DELIMITER $$
CREATE PROCEDURE ifProc3()
BEGIN
DECLARE debuteDate DATE; -- 데뷔 일자
DECLARE curDate DATE; -- 오늘
DECLARE days INT; -- 활동한 일수
SELECT debut_date INTO debuteDate
FROM market_db.member
WHERE mem_id = 'APN';
SET curDate = CURRENT_DATE();
SET days = DATEDIFF(curDate, debuteDate);
IF (days/365) >= 5 THEN -- 5년이 지났다면
SELECT CONCAT('데뷔한 지 ', days, '일이 지났습니다.');
ELSE
SELECT CONCAT('데뷔한 지 ', days, '일 밖에 안되었네요. 더 열심히 하세요.');
END IF;
END $$
DELIMITER ;
Call ifProc3();CASE문
CASE문의 기본형식은 다음과 같다.
CASE
WHEN 조건1 THEN
SQL 문장들
WHEN 조건2 THEN
SQL 문장들
ELSE
모두 해당 안될 경우 실행되는 SQL 문장들
END CASE;WHILE문
WHILE문의 기본형식은 다음과 같다.
WHILE <조건식> D0
SQL 문장들
END WHILE;WHILE문 활용 예시 👇
DROP PROCEDURE IF EXISTS whileProc;
DELIMITER $$
CREATE PROCEDURE whileProc()
BEGIN
DECLARE i INT; -- 1에서 100까지 증가할 변수
DECLARE hap INT; -- 더한 값을 누적할 변수
SET i = 1;
SET hap = 0;
WHILE (i <= 100) DO
SET hap = hap + i; -- hap의 원래의 값에 i를 더해서 다시 hap에 넣으라는 의미
SET i = i + 1; -- i의 원래의 값에 1을 더해서 다시 i에 넣으라는 의미
END WHILE;
SELECT '1부터 100까지의 합 ==>', hap;
END $$
DELIMITER ;
CALL whileProc();데이터베이스 스케줄러
MySQL 스케줄러 확인 및 실행 취소 쿼리
1. 이벤트 스케줄러 활성화 상태 확인
SHOW VARIABLES LIKE 'event_scheduler';2. 모든 스케줄러(이벤트) 목록 조회
SELECT
EVENT_NAME,
EVENT_SCHEMA,
STATUS,
EVENT_TYPE,
EXECUTE_AT,
INTERVAL_VALUE,
INTERVAL_FIELD,
LAST_EXECUTED,
STARTS,
ENDS
FROM information_schema.EVENTS
WHERE EVENT_SCHEMA = 'fanplus';3. 특정 스케줄러 상세 정보 확인
SHOW CREATE EVENT fanplus.이벤트명;4. 특정 스케줄러 비활성화 (실행 취소)
-- 스케줄러 일시 중지
ALTER EVENT fanplus.이벤트명 DISABLE;5. 특정 스케줄러 완전 삭제
DROP EVENT IF EXISTS fanplus.이벤트명;6. 비활성화된 스케줄러 다시 활성화
ALTER EVENT fanplus.이벤트명 ENABLE;7. 현재 실행 중인 프로세스 확인
SHOW PROCESSLIST;
-- 또는 상세 조회
SELECT * FROM information_schema.PROCESSLIST
WHERE COMMAND != 'Sleep';8. 특정 프로세스 강제 종료
KILL 프로세스_ID;동적 SQL
PREPARE와 EXECUTE
PREPARE는 SQL문을 실행하지는 않고 미리 준비하는 것이고 EXECUTE는 준비된 SQL문을 실행하는 것이다.
실행한 후에 꼭 DEACLLOCATE PREPARE로 문장을 해제해주는 것이 바람직히다.
use market_db;
PREPARE myQuery FROM 'SELECT * FROM member WHERE mem_id = "BLK"';
EXECUTE myQuery;
DEALLOCATE PREPARE myQuery;실시간으로 필요한 값을 쿼리의 ?로 할당해놓은 후 EXECUTE할 때 값을 넣어주는 방식으로 사용할 수 있다.
DROP TABLE IF EXISTS gate_table;
CREATE TABLE gate_table (id INT AUTO_INCREMENT PRIMARY KEY, entry_time DATETIME);
SET @curDate = CURRENT_TIMESTAMP(); -- 현재 날짜와 시간
PREPARE myQuery FROM 'INSERT INTO gate_table VALUES(NULL, ?)';
EXECUTE myQuery USING @curDate; -- ? 부분에 curDate를 넣어줌
DEALLOCATE PREPARE myQuery;
SELECT * FROM gate_table;제약조건
제약조건은 데이터베이스 테이블의 특정 열에 적용되어 데이터의 정확성과 무결성을 유지하는 데 도움을 주는 규칙 또는 제한을 의미하며, 쉽게 테이블의 특정 열에 적용되는 규칙이라고 생각하면 된다.
기본 키(Primary Key)와 외래 키(Foreign Key)가 대표적인 제약조건으로써
Primary Key
테이블을 생성할 때 데이터를 구분할 수 있는 식별자를 Primary Key라고 할 수 있다.
Primary Key를 지정하는 방법은 2가지가 있다.
첫 번째 방법 : 컬럼의 오른쪽에 명시
CREATE TABLE member (
mem_id CHAR(8) PRIMARY KEY,
mem_name VARCHAR(20) NOT NULL,
height TINYINT UNSINGED NULL,
);두 번째 방법 : 쿼리 맨 마지막에 명시
CREATE TABLE member (
mem_id CHAR(8) NOT NULL,
mem_name VARCHAR(20) NOT NULL,
height TINYINT UNSINGED NULL,
PRIMARY KEY (mem_id)
);Foreign Key
Foregin Key는 두 테이블 사이의 관계를 연결해줄 때 사용하는 제약조건이다.
기본형은
FOREIGN KEY(현재_테이블의_컬럼명) REFERENCES 관계_맺을_테이블(관계_맺을_테이블의_컬럼명)예시
DROP TABLE IF EXISTS buy, member;
CREATE TABLE member
( mem_id CHAR(8) NOT NULL PRIMARY KEY,
mem_name VARCHAR(10) NOT NULL,
height TINYINT UNSIGNED NULL
);
CREATE TABLE buy
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
buy_member_id CHAR(8) NOT NULL,
prod_name CHAR(6) NOT NULL,
FOREIGN KEY(buy_member_id) REFERENCES member(mem_id)
);ON DELETE/UPDATE CASCADE
- ON UPDATE CASCADE : 부모 테이블의 데이터가 수정되면 자식 테이블의 데이터도 수정
- ON DELETE CASCADE : 부모 테이블의 데이터가 삭제되면 자식 테이블의 데이터도 삭제
use market_db;
DROP TABLE IF EXISTS buy;
CREATE TABLE buy
( num INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
mem_id CHAR(8) NOT NULL,
prod_name CHAR(6) NOT NULL
);
ALTER TABLE buy
ADD CONSTRAINT
FOREIGN KEY(mem_id) REFERENCES member(mem_id)
ON UPDATE CASCADE
ON DELETE CASCADE;위와 같이 테이블 2개를 선언했다고 가정하자. 위의 상황에서 buy에 데이터를 입력하고
INSERT INTO buy (mem_id, prod_name) VALUES('BLK', '지갑');
INSERT INTO buy (mem_id, prod_name) VALUES('BLK', '맥북');member 테이블의 값을 수정했는데 buy의 값도 변경된 것을 확인할 수 있다.
UPDATE member SET mem_id = 'PINK' WHERE mem_id='BLK';
SELECT * FROM buy; -- mem_id가 전부 PINK로 바뀌어 있음이는 DELETE에 적용해보아도 동일하게 동작한다.
DELETE FROM member WHERE mem_id = 'PINK';
SELECT * FROM buy; -- 아무것도 출력되지 않음CHECK
CHECK 제약조건은 테이블에 입력되는 데이터의 유효성을 검사하는 제약조건이다.
예를 들어서 height이라는 컬럼이 있다고 가정할 때 100 이상 마이너스가 지정되지 않도록 하기 위해서 다음과 같이 제약 조건을 둘 수 있다.
DROP TABLE IF EXISTS user;
CREATE TABLE user (
id BIGINT not null AUTO_INCREMENT primary key ,
name VARCHAR(20) not null,
height TINYINT UNSIGNED NULL CHECK ( height >= 100 )
);기본값 정의
DEFAULT를 활용해서 기본값을 정의할 수 있다.
height TINYINT UNSIGNED NULL DEFAULT 160