컴퓨터 밑바닥의 비밀 Chapter 2 : 프로그램이 실행되었지만, 뭐가 뭔지 하나도 모르겠다
2.1 운영 체제, 프로세스, 스레드
2.1.1 모든 것은 CPU에서 시작된다
- CPU는 사실 스레드, 프로세스, 운영 체제 같은 개념을 전혀 알지 못함.
- CPU는 메모리에서 명령을 하나 가져와서 이 명령을 실행한 후 다시 명령을 가져오는 작업만을 함.
- CPU는 PC(Program Counter)라고 불리는 레지스터에서 명령어를 가져옴.
- PC 레지스터는 값을 하나씩 옮기거나 아니면 JMP 연산을 통해서 다음 PC 레지스터의 값을 변경함.
- 최초의 PC 레지스터 값은 메모리에 저장되어 있는데, 메모리에 저장된 명령어는 디스크에 저장된 실행 파일에서 적재되고 그 실행 파일은 컴파일러로 생성됨.
2.1.2 CPU에서 운영 체제까지
- 프로그램을 실행시키기 위해서는 프로그램을 적재할 수 있는 적절한 크기의 메모리 영역을 찾아야 함.
- CPU 레지스터를 초기화하고 함수의 진입 포인트(Entry Point)를 찾아 PC 레지스터를 설정해야 함.
- 한 번에 하나의 프로그램만 실행 가능함.
- 모든 프로그램은 사용할 하드웨어를 직접 특정 드라이버와 연결해야 하며, 그렇지 않으면 프로그램이 외부 장치를 전혀 사용할 수 없음.
- printf 같은 함수를 직접 구현해야 함.
- 위 같은 상황을 해주는 적재 도구(loader)를 개발.
- 하나의 코어로도 A 프로그램을 실행하다가 B 프로그램을 실행하면 동시에 실행하는 것처럼 보임.
- 실행 중인 프로그램을 관리해야할 필요성이 생김.
- 프로그램이 어디까지 실행중인이 어떤 데이터를 담고 있는지 등을 담을 상황 정보(context)가 필요해짐. 👉 프로세스라고 명명.
- 👉 이러한 동작을 해주는 것을 운영체제라고 명명함.
2.1.3 프로세스는 매우 훌륭하지만, 아직 불편하다
- 동일 프로세스 내에서 A라는 함수가 있고 B라는 함수가 있다고 할 때 A 함수가 3분이 걸리고 B 함수가 4분이 걸리면 직렬처리시 7분이라는 시간이 걸림.
- A 라는 함수를 프로세스 A로 만들고 B라는 함수를 프로세스 B로 만들어 병렬처리를 하면 4분이 걸리지만 두 값을 이용해서 뭔가 연산을 한다면 프로세스 간의 통신이 필요함.
- 프로세스 생성은 큰 비용임.
- 프로세스마다 자체적인 주소 공간을 가지고 있기 때문에 프로세스 간 통신은 프로그래밍하기에 더 복잡함.
- A 라는 함수를 프로세스 A로 만들고 B라는 함수를 프로세스 B로 만들어 병렬처리를 하면 4분이 걸리지만 두 값을 이용해서 뭔가 연산을 한다면 프로세스 간의 통신이 필요함.
2.1.4 프로세스에서 스레드로 진화
- 하나의 프로세스에 속한 기계 명령어를 CPU 여러 개에서 동시에 실행할 수 있음.
- CPU 여러 개가 한 지붕 아래에 있는 것과 마찬가지로 공유 프로세스 주소 공간에서 동일한 프로세스에 속한 명령어를 동시에 실행 가능.
- 다시 말해 하나의 프로세스 안에 여러 실행 흐름이 존재할 수 있음.
- 👉 이러한 실행 흐름을 **스레드(thread)**라고 부름.
- 다중 스레드는 상호 배제와 동기화를 이용해서 공유 리소스 문제를 명시적으로 직접 해결해야 한다는 문제가 발생.
2.1.5 다중 스레드와 메모리 구조
- 모든 스레드는 각자 자신만의 스택 영역을 가지는데, 스레드가 이를 인지하고 있는 것이 매우 중요함.
2.1.6 스레드 활용 예
- 서버가 하나의 요청을 받으면 해당 작업을 처리하는 스레드를 생성하고 처리가 완료되면 스레드를 종료하면 된다고 간단하게 생각할지도 모름.
- 이 방법은 일반적으로 요청당 스레드(thread-per-request)라고 부름.
- 요청이 들어올 때마다 매번 스레드가 생성된다는 의미로 긴 작업을 대상으론 잘 동작하지만 대량의 짧은 작업에서는 구현이 간단하지만 문제점이 있음.
- 스레드의 생성과 종료에 많은 시간을 허비.
- 스레드마다 각자 독립적인 스택 영역이 필요한데, 많은 수의 스레드를 생성하면 메모리와 기타 시스템 리소스를 너무 많이 소비함.
- 스레드 수가 많으면 스레드 간 전환(thread context switch)에 따른 부담이 증가함.
- 👉 이러한 문제를 해결하기 위해 스레드 풀(thread pool)이 탄생.
2.1.7 스레드 풀
- 스레드 여러 개를 미리 생성해 두고, 스레드가 처리할 작업이 생기면 해당 스레드에 처리를 요청하는 것.
- producer consumer 패턴과 유사함.
-
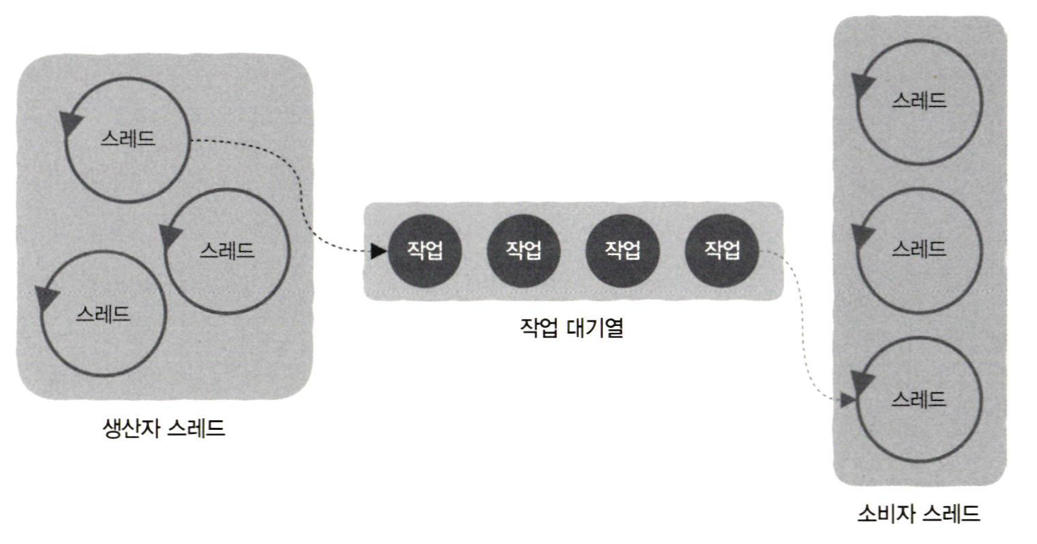
2.1.8 스레드 풀의 스레드 수
- CPU 바운드에선 CPU의 코어수와 거의 동일하게 IO Bound에선 테스트 결과에 따라 다르게 하셈.
- CPU 바운드는 스레드 수가 적은게 좋지만 IO Bound는 스레드 수가 많은게 좋음.
2.2 스레드 간 공유되는 프로세스 리소스
- 아래 두 질문으로 시작.
- 스레드 간에는 어떤 프로세스 리소스를 공유하고 있을까?
- 스레드 전용 리소스에는 어떤 것이 있을까?
2.2.1 스레드 전용 리소스
-
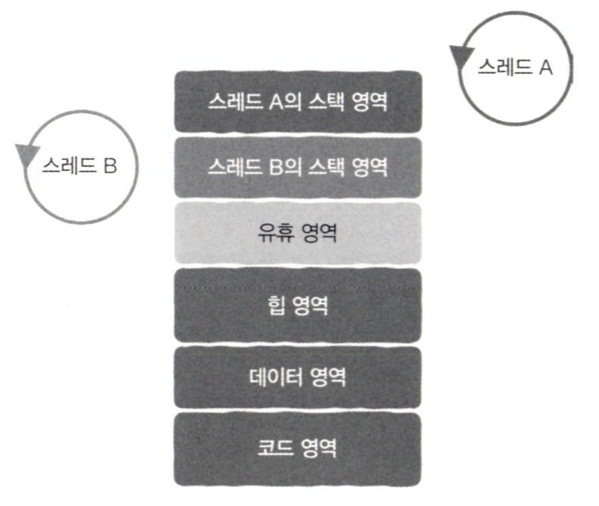
- 상태 변화 관점에서 보면 스레드는 사실 함수 실행임.
- 함수의 실행 시간 정보는 스택 영역을 구성하는 스택 프레임에 저장됨.
- 스택영역은 다음에 실행될 명령어 주소를 저장하는 PC 레지스터, 스레드 스택 영역에서 스택 상단(stack top) 위치를 저장하는 스택 포인터(stack pointer) 등으로 구성.
- 스레드는 프로세스 주소 공간에서 스택 영역을 제외한 나머지 영역을 모두 공유함.
2.2.2 코드 영역: 모든 함수를 스레드에 배치하여 실행할 수 있다
- 프로세스 주소 공간의 코드 영역에는 프로그래머가 작성한 코드, 더 정확하게는 컴파일한 후 생성된 실행 가능한 기계 명령어가 저장됨.
- 코드 영역은 스레드 간에 공유되므로 어떤 함수든지 모두 스레드에 적재하여 실행할 수 있음.
- 코드 영역은 읽기 전용임.
2.2.3 데이터 영역: 모든 스레드가 데이터 영역의 변수에 접근할 수 있다
- 데이터 영역은 전역 변수가 저장되는 곳임.
- 스레드간 공유됨.
2.2.4 힙 영역: 포인터가 핵심이다
- C/C++ 언어에서 malloc 함수와 new 예약어로 요청하는 메모리가 이 영역에 할당됨.
- 스레드간 공유됨.
2.2.5 스택 영역: 공유 공간 내 전용
- 실제 구현 측면에서 바라본다면 스택 영역은 엄밀하게 격리된 스레드 전용 공간은 아님.
- 프로세스 간에는 다른 프로세스의 주소 공간에 직접 접근하지 못하도록 보장하지만 서로 다른 스레드의 스택 영역 간에는 이런 보호를 위한 작동 방식이 존재하지 않음.
- 하나의 스레드가 다른 스레드의 스택 포인터를 가져올 수 있다면 해당 스레드는 다른 스레드의 스택 영역을 직접 읽고 쓸 수 있음.
2.2.6 동적 링크 라이브러리와 파일
-
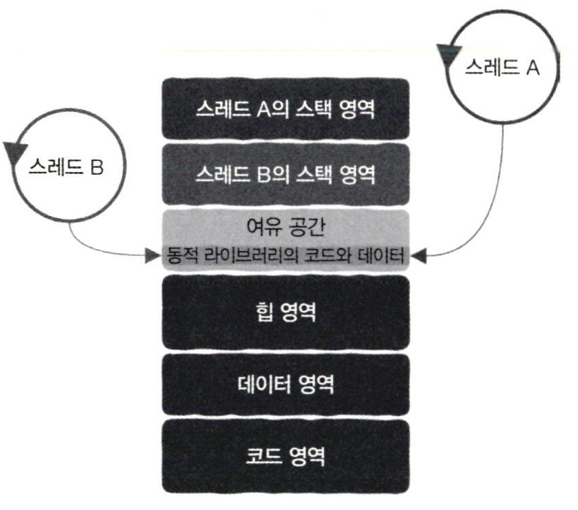
- 정적 프로그램은 시작할 때 적재되기 때문에 추가적인 작업이 필요하지 않지만 동적 링크는 프로그램을 시작할 때 또는 실행 중일 때 종속된 라이브러리의 코드와 데이터를 찾아서 프로세스 주소 공간에 넣는 링크 과정이 완료되어야 함.
- 이는 스택과 힙 사이의 여유 공간에 들어가며 모든 스레드가 공유해서 쓸 수 있음.
2.2.7 스레드 전용 저장소
// __thread 키워드를 사용하면 스레드 전용 저장소를 사용할 수 있음.
__thread int a = 1;- 이 영역에 저장된 변수는 모든 스레드에서 접근할 수 있지만 변수의 인스턴스는 각각의 스레드에 속함.
- 따라서 하나의 스레드에서 변수 값을 변경해도 다른 스레드에는 반영되지 않음.
2.3 스레드 안전 코드는 도대체 어떻게 작성해야 할까?
2.3.1 자유와 제약
- 전용 리소스를 사용하는 스레드는 스레드 안전을 달성할 수 있음.
- 공유 리소스를 사용하는 스레드는 다른 스레드에 영향을 주지 않도록 하는 대기 제약 조건에 맞게 공유 리소스를 사용하면 스레드 안전을 달성할 수 있음.
2.3.2 스레드 안전이란 무엇일까?
- 스레드들이 어떤 순서로 호출되든 간에 상관없이 올바른 결과가 나온다면, 이 코드를 스레드 안전이라고 함.
2.3.3 스레드 전용 리소스와 공유 리소스
- 함수의 지역 변수, 스레드의 스택 영역, 스레드 전용 저장소는 스레드 전용 리소스이며 그 외 힙, 데이터 영역, 코드 영역은 공유 리소스임.
2.3.4 스레드 전용 리소스만 사용하기
int func() {
int a = 1;
int b = 1;
return a + b;
}- 위 코드처럼 지역 변수만 사용해서 스레드 안전을 달성할 수 있음.
- 이런 코드를 무상태 함수라고 함.
2.3.5 스레드 전용 리소스와 함수 매개변수
- 함수 매개변수를 값으로 전달(call by value)하는 경우라면 문제 없지만 참조로 전달(call by reference)하는 경우에는 문제가 발생할 수 있음.
int func(int* num) {
++(*num);
return *num;
}- 포인터가 힙 영역에 저장된 동일한 변수를 가리키고 있다면, 해당 변수는 두 스레드가 공유하는 리소스로 간주됨.
2.3.6 전역 변수 사용
- 만약 사용되는 전역 변수가 읽기만 한다면 스레드 안전과 관련 없지만 읽기와 쓰기가 모두 발생 한다면 스레드 안정을 보장할 수 없음.
2.3.7 스레드 전용 저장소
- thread local storage(TLS)를 사용하면 스레드 안전을 달성할 수 있음.
2.3.8 함수 반환값
- 함수가 값을 반환하는 경우가 return by value라면 스레드 안전을 보장할 수 있지만 return by reference라면 스레드 안전을 보장할 수 없음.
- 예시 👇
-
int* func() { int a = 1; return &a; }
2.3.9 스레드 안전이 아닌 코드 호출하기
- 스레드 안전이 아닌 코드 앞에 락을 걸어서 스레드 안전을 보장할 수 있음.
int func() {
mutex l;
l.lock();
int a = 1;
l.unlock();
return a;
}2.3.10 스레드 안전 코드는 어떻게 구현할까?
- 스레드 전용 저장소(thread local storage, TLS) 사용.
- 전용 리소스 읽기 전용(read-only)으로 사용.
- 원자성 연산(atomic operation) 사용. (ex. std::atomic)
- 동기화 시 상호 배제. (ex. mutex, semaphore)