데이터 베이스 엔지니어링
ACID
- PostgreSQL은 Non-Repeatable Read에서도 Pathom Read를 방지할 수 있다.
Eventual Consistency
예를 들어서 두 테이블이 연관관계를 가지고 있다고 가정하자.
아래와 같이 Post와 Vote의 1:N 관계의 연관관계가 있다고 가정할 때 만약에 1번 포스트의 투표수가 1개라면 postId로 연관 되어있는 vote 테이블의 데이터 역시 1개여야 한다.
하지만 vote를 업데이트하는 시점에 post를 읽어오게 되면 vote 테이블의 vote 갯수는 2개이지만 post 테이블의 voteCount는 1개이다.
이러한 상황을 Eventual Consistency라고 한다.
CREATE TABLE post (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
content TEXT NOT NULL
voteCount INT DEFAULT 0
);
CREATE TABLE vote (
id SERIAL PRIMARY KEY,
postId INT NOT NULL,
voteType INT NOT NULL,
FOREIGN KEY (postId) REFERENCES post(id)
);또 다른 예시로 테이블의 구조를 CQRS 패턴으로 설계했다고 가정할 때 READ 테이블과 WRITE 테이블간의 데이터 불일치(데이터 베이스가 여러개로 분산된 경우도 마찬가지)가 발생할 수 있는데 이런식으로 데이터가 여러 곳에 올라가 있어서 발생할 수 있는 문제를 Eventual Consistency라고 한다.
데이터베이스 내부 이해
- PostgreSQL은 8KB의 Page를 기본 크기로 갖고 MySQL은 16KB의 Page를 기본 크기로 갖는다.
- PostgreSQL은 기본키가 Primary KEY(클러스터형 index)가 아니다.
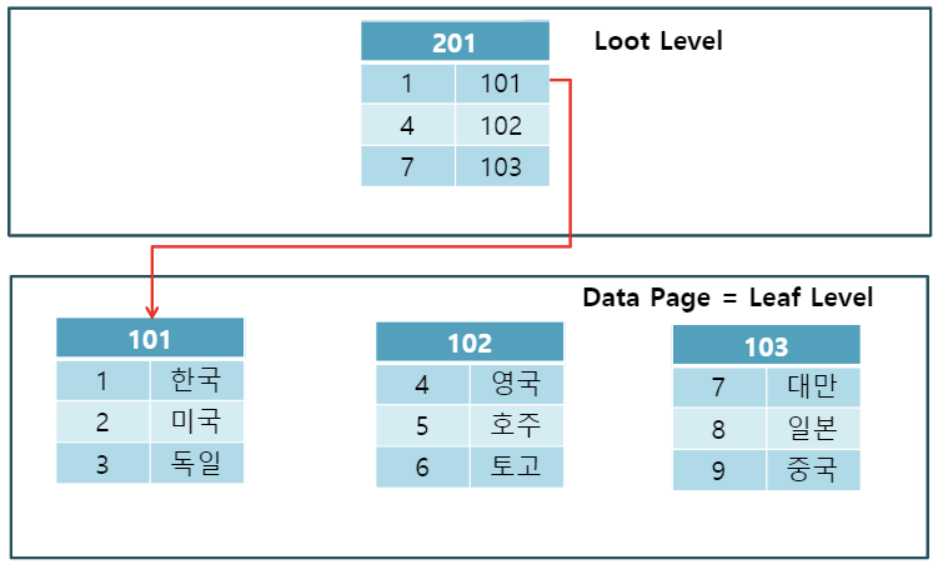
- 🤔 클러스터형 인덱스란?
- 테이블내에 한 개만 가질 수 있음
- 내용 자체가 순서대로 정렬되어 있음
- Heap에 데이터가 Page 구조로 저장이 되는데 이 때 순서대로 Page에 데이터가 저장되고 그 순서를 가지고 데이터를 찾아가는 방식
-
- 🤔 클러스터형 인덱스란?
Row Base DB vs Column Base DB
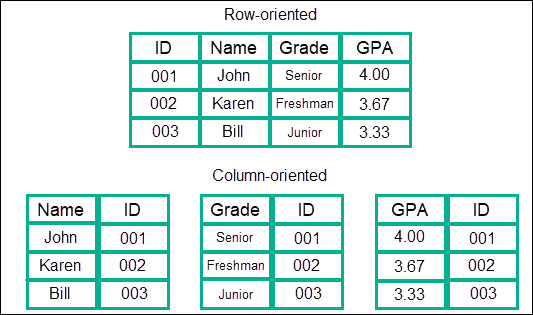
- Row Base DB: MySQL, PostgreSQL
- 데이터를 쓰고, 삭제하는 작업에 유리함
- 데이터를 읽는 작업이 Column Base DB에 비해 느림
- Column Base DB:
- 데이터를 읽는 작업에 유리함
- 데이터를 쓰고, 삭제하는 작업이 Row Base DB에 비해 느림
- 만약에 6개의 컬럼을 가진 Column base Table의 한 Row를 수정하기 위해서는 6번의 탐색 및 삭제 작업이 필요하다.
DB 인덱싱
인덱스는 기존 테이블 위에 구축하고 할당하는 데이터 구조이며 B Tree나 LSM Tree와 같은 데이터 구조를 사용한다.
100만개의 데이터를 가진 테이블 생성
- 테이블 생성
create table temp(i int);- 100만개 데이터 생성
insert into temp(i) select random() * 100 -- 0~100까지 랜덤
from generate_series(0, 1000000); -- 100만개 생성- 생성된 숫자 확인
select count(*) from temp; -- 1000001 100만개의 데이터 조회 성능 비교
- 테스트할 Table
create table employees( id serial primary key, name text);
create or replace function random_string(length integer) returns text as
$$
declare
chars text[] := '{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F,G,H,I,J,K,L,M,N,O,P,Q,R,S,T,U,V,W,X,Y,Z,a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z}';
result text := '';
i integer := 0;
length2 integer := (select trunc(random() * length + 1));
begin
if length2 < 0 then
raise exception 'Given length cannot be less than 0';
end if;
for i in 1..length2 loop
result := result || chars[1+random()*(array_length(chars, 1)-1)];
end loop;
return result;
end;
$$ language plpgsql;
insert into employees(name)(select random_string(10) from generate_series(0, 1000000));Index 사용 조회
- ID만 조회시
explain analyze select id from employees where id = 2000;결과
Heap Fetches가 0인 이유는 ID에 해당하는 Heap으로 가서 데이터를 가져오지 않고 Index만으로 데이터를 가져왔기 때문이다. 찾으려는 정보가 인덱스에 있다면 가장 좋은 쿼리가 될 것이다.
Index Only Scan using employees_pkey on employees (cost=0.42..4.44 rows=1 width=4) (actual time=0.063..0.064 rows=1 loops=1)
Index Cond: (id = 2000)
Heap Fetches: 0
Planning Time: 0.143 ms
Execution Time: 0.082 ms- Name 조회시
explain analyze select name from employees where id = 5000;결과
인덱스에서 ID를 찾았지만 Name을 찾기 위해서 Heap으로 가서 데이터를 가져왔기 때문에 성능이 떨어진다.
explain analyze select name from employees where id = 5000;Index 사용하지 않은 조회
- id 조회 쿼리
explain analyze select id from employees where name = 'Zs';결과
Parellel Seq Scan을 사용했다는 정보가 나오는데 이는 병렬로 테이블을 FullScan 했다는 것이다.
explain analyze select id from employees where name = 'Zs';
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on employees (cost=0.00..10310.34 rows=2 width=4) (actual time=1.351..27.591 rows=11 loops=3)
Filter: (name = 'Zs'::text)
Rows Removed by Filter: 333323
Planning Time: 0.473 ms
Execution Time: 31.093 msemployees.name Index 생성 후 조회
- 인덱스 생성
create index employees_name on employees(name);- 조회
explain analyze select id from employees where name = 'Zs';- 실행 결과
실행 속도가 31ms에서 0.298ms로 줄어들었다.
Bitmap Heap Scan on employees (cost=4.47..27.93 rows=6 width=4) (actual time=0.042..0.268 rows=32 loops=1)
Recheck Cond: (name = 'Zs'::text)
Heap Blocks: exact=32
-> Bitmap Index Scan on employees_name (cost=0.00..4.47 rows=6 width=0) (actual time=0.031..0.031 rows=32 loops=1)
Index Cond: (name = 'Zs'::text)
Planning Time: 0.278 ms
Execution Time: 0.298 ms쿼리 플래너와 옵티마이저
테이블 생성 쿼리
create table grades (
id serial primary key,
g int,
name text
);
insert into grades (g,
name )
select
random()*100,
substring(md5(random()::text ),0,floor(random()*31)::int)
from generate_series(0, 500);
vacuum (analyze, verbose, full);
explain analyze select id,g from grades where g > 80 and g < 95 order by g;Explain Keyword 사용
- 쿼리
explain select * from grades;결과
아래 결과에서 0.00 ~ 9.01은 첫 번째 Row를 가져온 시간과 마지막 Row를 가져온 시간이며 ms 단위이다.
Seq Scan on grades (cost=0.00..9.01 rows=501 width=23)- Index가 걸린 Column에 Order By를 적용하는 경우
explain select * from grades Order by id;결과
첫 번째 Row를 들고온 시간이 위의 0.00과 다르게 0.27이 되어있는 것을 확인할 수 있는데 0.27이 SELECT가 수행되기 전의 Order by가 수행된 시간이다.
Index Scan using grades_pkey on grades (cost=0.27..30.79 rows=501 width=23)- Index가 없는 행에 Order by 사용
explain select * from grades Order by name;결과
Sort (cost=31.48..32.73 rows=501 width=23)
Sort Key: name
-> Seq Scan on grades (cost=0.00..9.01 rows=501 width=23)Postgres의 Scan 방식
- 만약에 스캔 해야할 데이터가 많다면 Seq Scan을 사용
- 만약에 스캔 해야할 데이터가 적다면 Index Scan을 사용
- PK가 아닌 Column에 Index를 걸었다면 Bitmap Index Scan을 사용
-

- Bitmap Index란 각 Bitmap에 해당하는 Page를 가지고 있는 Index를 의미함
- Bitmap Index Scan은 다른 Index Scan과 조합해서 사용할 수 있음
-
KEY vs NON KEY 열 DB 인덱싱
테이블 생성 쿼리
create table students (
id serial primary key,
g int,
firstname text,
lastname text,
middlename text,
address text,
bio text,
dob date,
id1 int,
id2 int,
id3 int,
id4 int,
id5 int,
id6 int,
id7 int,
id8 int,
id9 int
);
insert into students (g,
firstname,
lastname,
middlename,
address ,
bio,
dob,
id1 ,
id2,
id3,
id4,
id5,
id6,
id7,
id8,
id9)
select
random()*100,
substring(md5(random()::text ),0,floor(random()*31)::int),
substring(md5(random()::text ),0,floor(random()*31)::int),
substring(md5(random()::text ),0,floor(random()*31)::int),
substring(md5(random()::text ),0,floor(random()*31)::int),
substring(md5(random()::text ),0,floor(random()*31)::int),
now(),
random()*100000,
random()*100000,
random()*100000,
random()*100000,
random()*100000,
random()*100000,
random()*100000,
random()*100000,
random()*100000
from generate_series(0, 50000000);
vacuum (analyze, verbose, full);
explain analyze select id,g from students where g > 80 and g < 95 order by g;Index Scan
만약에 아래 쿼리로 g에 대해서 인덱스를 생성하고 조회를 한다면 당연히 인덱스 스캔을 사용할 것이다.
- 인덱스 생성
create index on students (g);- 조회 쿼리
explain analyze select id,g from students where g > 10 and g < 25 order by g limit 50;결과
Limit (cost=0.56..101.66 rows=50 width=8) (actual time=0.058..0.255 rows=50 loops=1)
-> Index Scan using students_g_idx on students (cost=0.56..13751993.62 rows=6801250 width=8) (actual time=0.057..0.249 rows=50 loops=1)
Index Cond: ((g > 10) AND (g < 25))
Planning Time: 0.153 ms
Execution Time: 0.271 msOnly Index Scan
하지만 위에서 만든 index를 지우고 id를 조회하기 때문에 index에 id를 포함하게 된다면 Only Index Scan을 사용하고 그러면 Heap을 조회할 일이 없어지기 때문에 성능이 향상될 것이다. 하지만 index에 포함되는 데이터가 많아지면 인덱스가 디스크에 저장될 수 있고 그럴경우 성능은 더 떨어질 수 있다. 즉, Only Index Scan이 반드시 가장 좋은 것은 아니다.
create index on students (g) include (id);
drop index students_g_idx;- 조회 쿼리
explain analyze select id,g from students where g > 10 and g < 25 order by g limit 50;결과
Limit (cost=0.56..32.75 rows=50 width=8) (actual time=0.020..0.026 rows=50 loops=1)
-> Index Only Scan using students_g_id_idx on students (cost=0.56..4378641.68 rows=6801250 width=8) (actual time=0.019..0.023 rows=50 loops=1)
Index Cond: ((g > 10) AND (g < 25))
Heap Fetches: 0
Planning Time: 0.283 ms
Execution Time: 0.038 ms성능 개선을 위한 데이터베이스 인덱스 결합
아래와 같은 테이블이 있다고 가정하자.
insert into test (math, physics) select random()*100, random()*100 from generate_series(0, 1000000);
create index math_idx on test (math);
create index physics_idx on test (physics);현재 math, physics index가 생성된 상태에서 아래 쿼리를 사용하면 복합 쿼리를 사용하게 된다.
- 쿼리
실행결과
Limit (cost=226.15..262.14 rows=10 width=12) (actual time=1.452..1.482 rows=10 loops=1)
-> Bitmap Heap Scan on test (cost=226.15..600.44 rows=104 width=12) (actual time=1.451..1.480 rows=10 loops=1)
Recheck Cond: ((math = 10) AND (physics = 20))
Heap Blocks: exact=10
-> BitmapAnd (cost=226.15..226.15 rows=104 width=0) (actual time=1.432..1.432 rows=0 loops=1)
-> Bitmap Index Scan on math_idx (cost=0.00..111.42 rows=10000 width=0) (actual time=0.707..0.708 rows=10057 loops=1)
Index Cond: (math = 10)
-> Bitmap Index Scan on physics_idx (cost=0.00..114.42 rows=10400 width=0) (actual time=0.597..0.597 rows=10096 loops=1)
Index Cond: (physics = 20)
Planning Time: 0.089 ms
Execution Time: 1.498 ms복합 인덱스 사용
위에서 정의한 index를 모두 지우고 math와 physics에 대해서 복합 인덱스를 생성해준다.
- 인덱스 생성
create index on test (math, physics);- 조회 쿼리 수행 결과
그러면 쿼리 수행 결과가 월등히 향상된 것을 알 수 있다.
Limit (cost=0.42..41.01 rows=10 width=12) (actual time=0.019..0.032 rows=10 loops=1)
-> Index Scan using test_math_physics_idx on test (cost=0.42..422.49 rows=104 width=12) (actual time=0.018..0.030 rows=10 loops=1)
Index Cond: ((math = 10) AND (physics = 20))
Planning Time: 0.198 ms
Execution Time: 0.044 ms복합인덱스 사용시 주의사항
위에서 math, physics에 대해서 복합 인덱스를 생성했기 때문에 index는 기본적으로 math를 기준으로 정렬되어 있다. 그렇기 때문에 physics에 대해서는 index scan이 되지 않는다. 또한 OR 연산에도 index가 걸리지 않는다.
즉, 만약에 a. b. ab 모두를 조회할 때를 대비해서 a, b, ab에 대한 인덱스를 모두 생성하는 것은 멍청한 짓이다. ab 인덱스를 생성하고 b 인덱스만 따로 생성하면 a, b, ab에 대해서 모든 인덱스가 동작한다.
인덱스 생성시 쓰기 방지 및 우회
인덱스를 생성할 때는 쓰기가 중지가 된다. 이러한 점을 우회하기 위해서 Postgres는 Concurrent Index를 제공한다.
create index concurrently g on grades(g);Bloom Filter
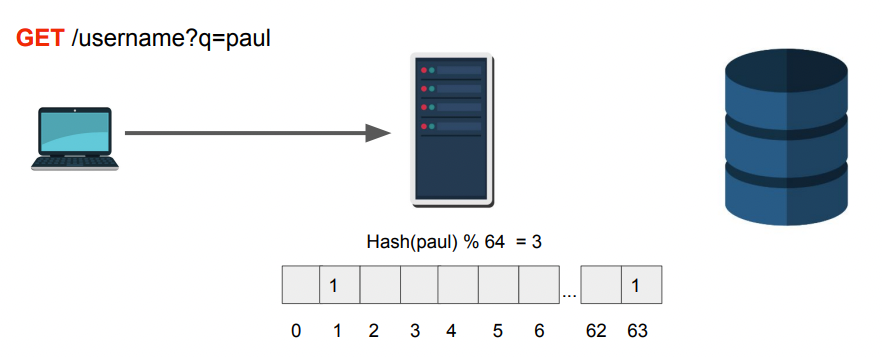
블룸 필터는 빠르게 원소가 집합에 속하는지 여부를 확인하는 확률적 데이터 구조입니다. 블룸 필터는 예를 들어서 닉네임을 찾는다고 가정할 때 닉네임이 있는지 없는지를 판별하기 위해서 64비트의 비트배열을 만들고 닉네임을 해싱해서 나온 비트에 대해서 0으로 세팅이 되어있다면 닉네임이 반드시 존재하지 않는다고 판단하는 방식이다. 비트가 1로 설정되있다고 해서 다른 해싱값이 해당 비트일 수 있기 때문에 반드시 존재한다고 판단하진 못하지만 조회하는 성능을 향상시킬 수 있는 방식이다.
인덱스 사용시 주의
- Like 연산은 인덱스를 타지 않는다.