Clean Architecture
Clean Architecture 원글 (opens in a new tab)
Code with Andrea 블로그 (opens in a new tab)
한국어로 잘 설명되 있는 blog (opens in a new tab)
SOLID
SOLID 원칙은 함수와 데이터 구조를 클래스로 배치하는 방법, 그리고 이들 클래스를 서로 결합하는 방법을 설명해준다.
여기서 클래스라는 단어를 사용했다고 해서 SOLID 원칙이 객체지향 프로그래밍에만 적용되는 것은 아니다. 여기서 말하는 클래스는 단순히 함수와 데이터를 결합한 집합을 말한다.
SOLID 원칙의 목적
중간 수준의 소프트웨어가 다음과 같은 특징을 가지도록 설계하는데 있다.
- 변경에 유연하다.
- 이해하기 쉽다.
- 많은 소프트웨어 시스템에 사용될 수 있는 컴포넌트의 기반이 된다.
SRP
SRP (Single Responsibility Principle) : 단일 책임 원칙
각 소프트웨어 모듈은 변경의 이유가 하나, 단 하나여야만 한다.
여기서 변경의 이유가 단 하나여야 한다는 이유란 무엇일까? 나중에 소프트웨어를 수정할 일이 생겨서 소프트웨어의 모듈 중 하나를 수정한다고 가정할 때, 그 이유가 UI의 문제, 데이터 베이스 연동의 문제, 데이터 베이스 쿼리의 문제 등 다양하게 나올 수 있지만 이러한 이유가 단 하나의 모듈에서 나오면 안된다는 것이다.
잘 정리되어 있는 블로그 : https://dding9code.tistory.com/32 (opens in a new tab)
SRP에 어긋나는 징후들
징후 1: 우발적 중복
Employee라는 클래스에
- calculatePay
- reportHours
- save 라는 메서드가 있을 때 이를 사용하는 액터는 각각
- calculatePay (CFO)
- reportHours (COO)
- save (CTO) 이런 식으로 계산이 된다. 이는 필자가 말하는 하나의 모듈 하나의 액터의 원칙에 어긋나는 것이다.
하나의 모듈은 하나의, 오직 하나의 액터(사용자나 이해관계자의 집단)에 대해서만 책임을 져야 한다.
SRP는서로 다른 액터가 의존하는 코드를 서로 분리하라고 말한다.
징후 2: 병합
다양한 메서드가 하나의 클래스에 생기는 경우
예를 들어서 CTO 팀에서 데이터베이스의 Employee 테이블 스키마를 약간 수정하기로 결정했는데 인사 담당자가 속한 COO 팀에서 reportHours() 메서드의 보고서 포맷을 변경하기로 결정한 경우 두 팀의 개발자가 Employee 클래스를 Chekout받은 후 변경사항을 적용하기 시작한다. 안타깝게도 이런 변경사항은 충돌이 나고 결론적으로 병합이 발생한다.ㅌㅌㅌㅌ
- 해결책 :
- 간단한 데이터 구조인 클래스를 하나 만들어서 메서드만 있는 다른 클래스로 분리 시킨다.

- 퍼사드 패턴
OCP
OCP (Open-Closed Principle) : 개방-폐쇄 원칙
기존 코드를 수정하기보다는 반드시 새로운 코드를 추가하는 방식으로 시스템의 행위를 변경할 수 있도록 설계해야만 소프트웨어 시스템을 쉽게 변경할 수 있다는 것이다.
즉, 수정엔 닫혀있고 확장에는 열려있어야 한다.
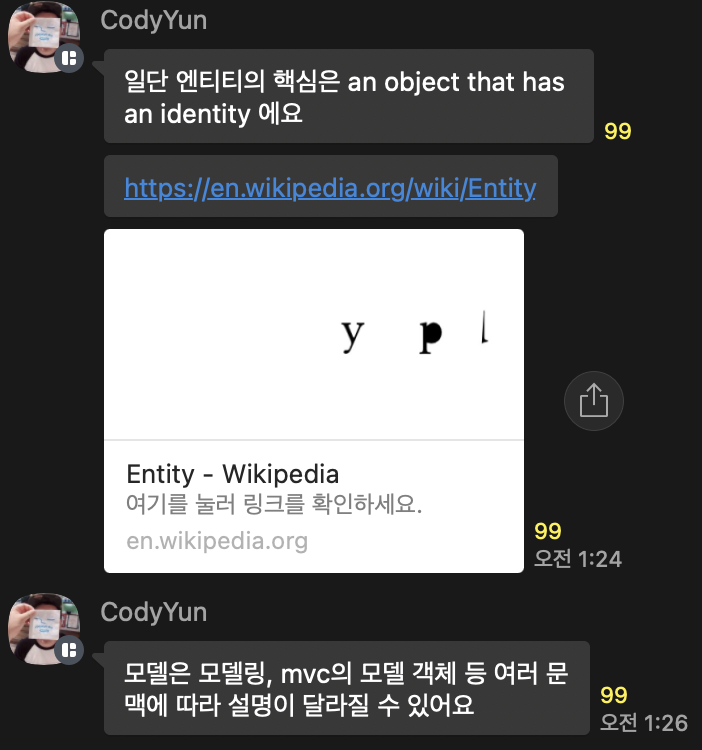
Interactor
Interactor는 OCP를 가장 잘 준수할 수 있는 곳에 위치한다. DB, Controller, Presenter, View에서 발생한 어떤 변경도 Interactor에 영향을 주지 않는다.
위의 사진에서 대표적인 예시로 FinancialDataGateway 인터페이스는 FinancialReportGenerator와 FinancialDataMapper 사이에 위치하는데, 이는 의존성을 역전시키기 위해서다. 만약에 FInancialDataGateway가 없다면 의존성이 Interactor 컴포넌트에서 Database 컴포넌트로 향하게 된다.
LSP
LSP (Liskov Substitution Principle) : 리스코프 치환 원칙
상호 대체 가능한 구성요소를 이용해 소프트웨어 시스템을 만들 수 있으려면, 이들 구성요소는 반드시 서로 치환 가능해야 한다는 계약을 반드시 지켜야 한다.
- GPT :
이 원칙을 좀 더 자세히 설명하자면, 만약 클래스 B가 클래스 A를 상속받는다면, 우리는 클래스 A의 객체를 클래스 B의 객체로 대체해도 프로그램이 문제없이 동작해야 한다는 것입니다.
이는 클래스 B의 모든 인스턴스가 클래스 A의 모든 인스턴스의 기능을 유지하면서 확장해야 함을 의미합니다.
예를 들어, '새' 클래스가 '비행동물' 클래스를 상속받는다고 가정해봅시다.
이 경우, '비행동물'을 나타내는 코드 어디서든 '새'를 사용해도 프로그램이 정상적으로 작동해야 합니다. 만약 '펭귄' 클래스가 '새' 클래스를 상속받는다면, 문제가 발생할 수 있습니다.
왜냐하면 펭귄은 날지 못하기 때문에 '비행동물'의 행동을 완전히 대체할 수 없습니다.
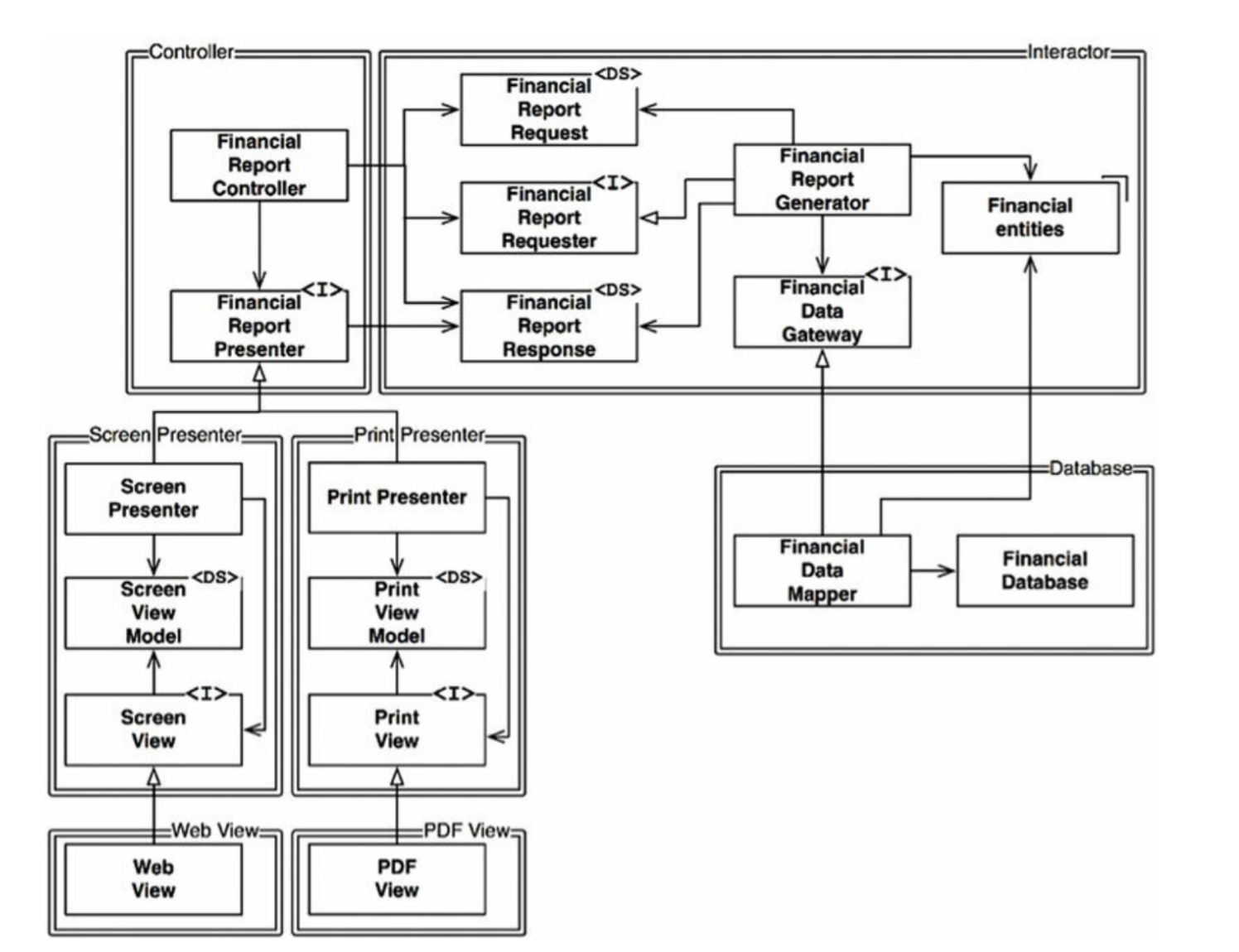
이 예제에서 Billing은 License를 호출하는데 License의 하위 타입인 Personal License나 BusinessLicense 중 어떤 것을 사용해도 문제가 없다.
이러한 예시가 LSP를 잘 준수하고 있다는 것을 보여준다.
ISP
ISP (Interface Segregation Principle) : 인터페이스 분리 원칙
소프트웨어 설계자는 사용하지 않은 것에 의존하지 않아야 한다.
- GPT :
즉, 하나의 "거대한" 인터페이스를 가진 대신에 여러 개의 작고, 명확한 역할을 하는 인터페이스를 가지는 것이 좋다는 것을 의미합니다.
이렇게 하면 각 인터페이스는 서로 다른 역할에 대해 의존성을 최소화하고, 필요한 기능만을 제공하게 됩니다.
예시
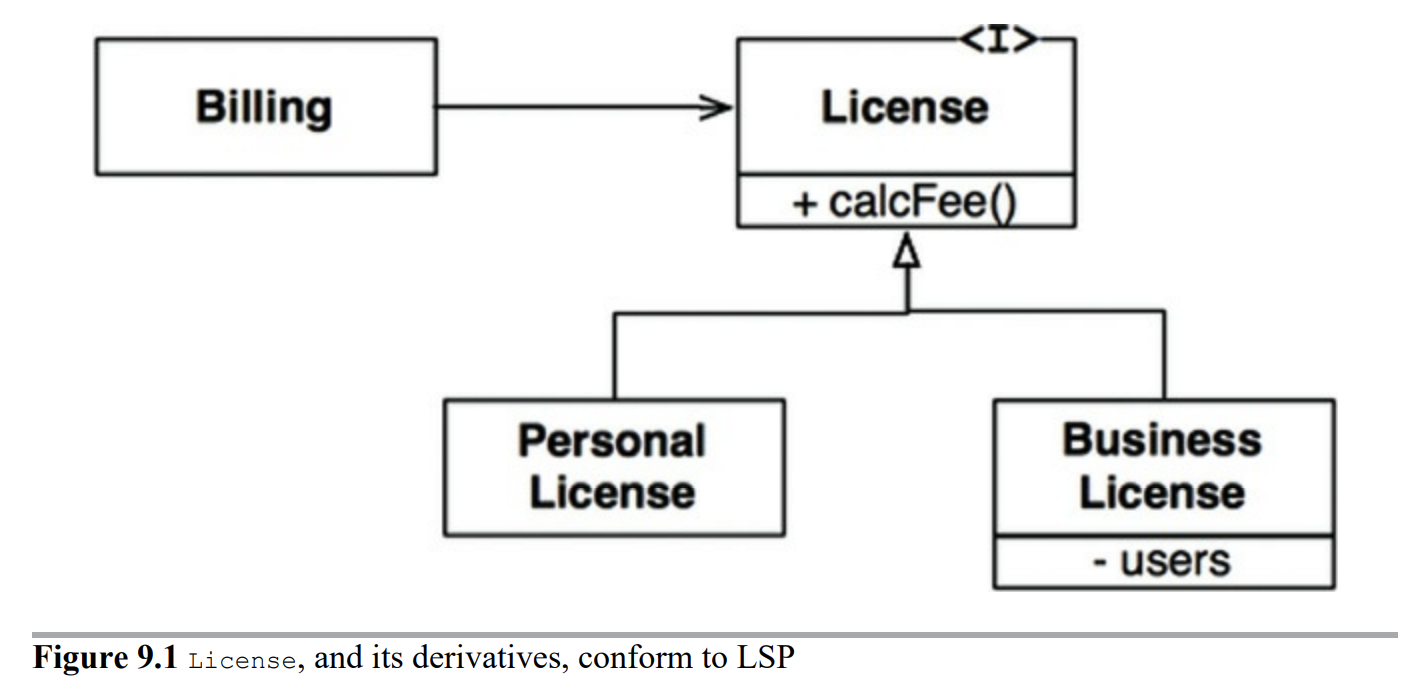
아래와 같은 그림에서 User1, User2, User3은 각각 OPS 클래스의 op1, op2, op3 메서드를 사용한다고 가정할 때 사용하지 않는 두 메서드에 의해서 의존성이 발생할 수 있다.
이러한 상황을 방지하기 위해서 아래와 같이 인터페이스를 분리해서 사용해줄 수 있다.

이를 코드로 보자면 아래와 같다.
public interface Worker {
void work();
void eat();
}
public class HumanWorker implements Worker {
public void work() {
// 작업하는 코드
}
public void eat() {
// 식사하는 코드
}
}
public class RobotWorker implements Worker {
public void work() {
// 작업하는 코드
}
public void eat() {
// 로봇은 먹지 않음. 그러나 이 메소드는 인터페이스에 있으므로 구현해야 함.
}
}DIP
DIP (Dependency Inversion Principle) : 의존성 역전 원칙
고수준 정책을 구현하는 코드는 저수준 세부사항을 구현하는 코드에 절대로 의존해서는 안 된다. 대신 세부사항이 정책에 의존해야 한다.
예시 코드
FirebaseAuthWrapper는 FirebaseAuth의 세부 구현에 대한 의존성을 제거하고 대신 AuthBase에 대한 의존성만들 가진다.
즉, FirebaseAuth의 내부 코드가 변경되더라도 AuthBase에 대한 의존성만을 지키면서 구현을 해주면 되며 AuthRepository는 이에 영향을 받지 않는다.
고수준 모듈이 저수준 모듈에 직접 의존하는 대신, 두 모듈 모두 추상화에만 의존하고 있으므로 이는 의존성 역전의 법칙의 적절한 예시이다.
abstract class AuthBase {
Stream<User?> authStateChanges();
User? get currentUser;
Future<void> userDelete();
Future<void> signOut();
}DI vs SI
Dynamic Injection
런타임 중에 의존성을 주입하는 프로세스를 말한다.
아래 예시를 보면 setter를 통해서 Service를 외부로부터 주입받고 있다.
이런 방식을 사용하면 런타임 중에 Service 객체를 변경할 수 있으므로 유연성이 향상된다.
public class Service {
public void serve() {
System.out.println("Service is serving");
}
}
public class Client {
private Service service;
public void setService(Service service) {
this.service = service;
}
public void doSomething() {
service.serve();
}
}Static Injection
아래 코드는 Service라는 의존성을 Client에서 직접 초기화 한다. 이런 경우 Service는 컴파일 타임에 의존성이 결정되며, 실행 중에 이를 변경하는 것은 불가능하다.
public class Service {
public void serve() {
System.out.println("Service is serving");
}
}
public class Client {
private Service service;
public Client() {
this.service = new Service();
}
public void doSomething() {
service.serve();
}
}Layer
Entity
이 클래스(레이어)는 데이터베이스, 사용자 인터페이스, 서드파티 프레임워크에 대한 고려사항들로 인해 오염되어서는 절대 안 된다.
Use case
사용자가 제공해야 하는 입력, 사용자에게 보여줄 출력, 그리고 해당 출력을 생성하기 위한 처리 단계를 기술한다.
엔티티 내의 핵심 업무 규칙과는 반대로, 유스케이스는 어플리케이션에 특화된 업무 규칙을 설명한다.
유스케이스만 봐서는 이 애플리케이션이 웹을 통해 전달되는지, 리치 클라이언트인지, 콘솔 기반인지, 아니면 순수한 서비스인지를 구분하기란 불가능하다.
즉, 유스케이스는 사용자 인터페이스를 제공하지 않는다.
Interface Adapter
데이터를 유스케이스와 엔티티에게 가장 편리한 형식에서 데이터베이스나 웹 같은 외부 에이전시에게 가장 편리한 형식으로 변환한다. 이 계층은 GUI의 MVC 아키텍처를 모두 포괄한다.
Framework & Driver
일반적으로 이 계층에서는 안쪽 원과 통신하기 위한 접합 코드 외에는 특별히 더 작성해야 할 코드가 그다지 많지 않다.
위에 해당되면 원의 개수가 어쩌고는 중요하지 않다.
좀 더 세부적으로 나눌 수 있다고 필자는 기술하였다.
이 글을 읽고 들었던 고민은 뷰는 반드시 프레임워크에 의존적이라고 생각하고 있었다.
그래서 뷰가 어떤 계층에 있어야 하는지에 대한 궁금증이 들었다.
왜냐하면 여지껏 봐왔던 대부분의 블로그들이 Presenter Layer라면서 View를 해당 Layer(여기서는 Interface Adapters Layer)에 포함시켰기 때문이다.
그리고 다음장을 펼치고 이 궁금증이 바로 해소되었다.
나는 view model이 Interface Adapters Layer이고 View가 Frameworks & Drivers Layer라고 생각했는데, 필자도 그렇게 생각하고 있었나보다.
Clean Architecture의 전형적인 케이스 👇

Clean Architecture 이모저모
Flutter Clean Architecture
-
data
- repository : API call or Local DB 등 데이터 서빙
- model
-
controller
- service(usecase)
- state : view 들의 state
-
presentation
- view : 보여지는 뷰
- widget : 분리된 위젯
- page : 라우팅을 위한 페이지 (page 하나에 TabBar등을 통해서 여러 개의 view가 존재할 수 있음)
-
etc : 위의 레이어 들의 하위에 올 수 있는 개념들
- helper : 패키지 등의 구현체
- base : interface
Spring Clean Architecture
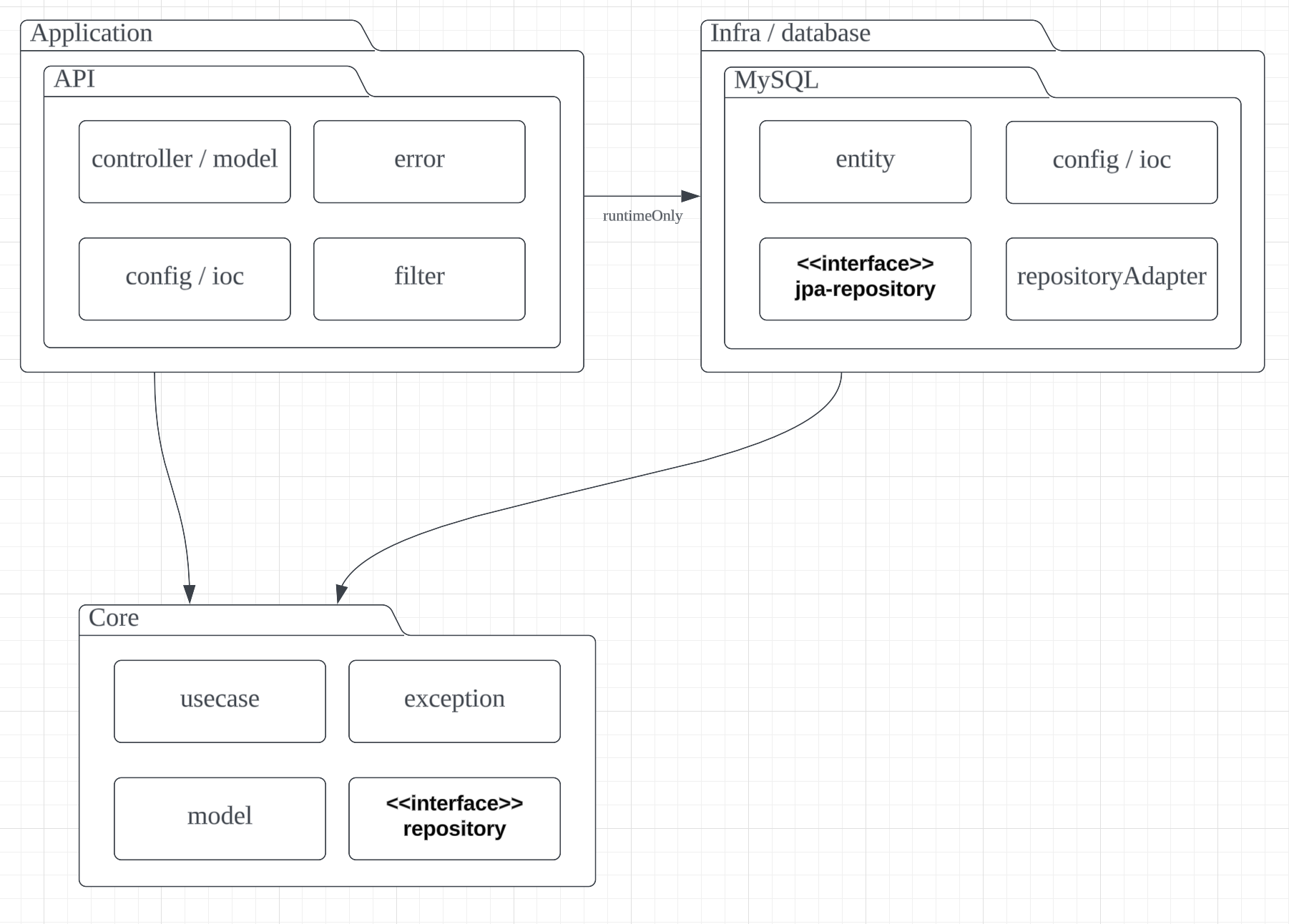
Controller -> Business -> Service <- Persistence
Q. persistence를 감싸는 Service Layer위에 Business Layer라던지가 없으니까 Service끼리 의존성이 생기는데 이게 괜찮은건가요?
여기선 persistence랑 service 모듈을 분리하지 않고 persistence 내부에 service를 둔다. 그 service를 repositoryAdapter 명명해서 사용한다.
- usecase = business
- repositoryAdapter = service
Cody님
- 요구사항이 복잡해지고 사용자의 눈높이가 높아져 단일 객체로 소프트웨어를 만드는건 불가능
- 여러 객체로 소프트웨어의 기능을 구현하다보니 교통 정리가 필요해짐
- 디자인 패턴이나 아키텍쳐나 solid 원칙이나 디미터의법칙 등 객체간의 교통 정리를 위한 여러 개념이 등장
- 그 중 클린 아키텍쳐는 객체간의 관심사를 엔티티, 유즈케이스, 인터페이스어댑터(컨트롤러, 프리젠터, 게이트웨이), 프레임워크와 드라이버(db, 프레임워크 등) 레이어로 분리한 아키텍쳐
- 클린아키텍쳐의 가장 중요한 규칙은 레이어간의 의존성 규칙인데, 내부 레이어는 외 레이어를 알면 안됨(내부 레이어에 외부 레이어의 클래스, 함수, 메서드, 프로퍼티를 포함한 어떤것도 사용되면 안됨)
- 따라서 레이어의 역할과 레이어간의 의존성이 중요
- 이러한 구조는 사용하는 프레임워크나 db, ui, 라이브러리 등으로 부터 독립적인 구조가되어 테스트 가능한 코드를 만들어줌(의존성이 약해져 자연스럽게 테스트 가능한 코드가 만들어짐)
- 올려주신 코드의 목적이 클린아키텍쳐와 폴더링인데, 사실 폴더링이 더 중요하다고 하셨는데요. 폴더링으론 의존성을 관리할 수 없어요. 폴더링으로 접근하게되면 클린아키텍쳐나 클린아키텍쳐로부터 파생된 여러 개념들의 네이밍만 가져다 쓰게되요. 클린 이키텍쳐 원글에도 보면 가장 중요한건 레이어의 분리와 레이어간의 의존성 규칙이에요. 내부 레이어는 외부레이어의 어떤것도 알면 안된다 라는 중요한 규칙을 지키기 위해 사용하는게 인터페이스를 이용한 추상화와 di입니다.
- 클린아키텍쳐는 구현에 대한 세부 지침이 안나와요. 그래서 핵사고날이나 오니온아키텍쳐를 많이 참고해서 만들구요.
추천 articles
starter_architecture_flutter_firebase
참조한 소스 코드 (opens in a new tab)
Async Value Error Handling
AsyncValueError를 핸들링하기 위해서 아래와 같은 스크린으로 일반화를 해놓고 error 상황일 때, 로딩 중일 때, data가 정상적으로 로딩이 되었을 때 각각 다른 화면을 보여준다.
JobEntriesScreen 에서의 사용
class JobEntriesScreen extends ConsumerWidget {
const JobEntriesScreen({super.key, required this.jobId});
final JobID jobId;
@override
Widget build(BuildContext context, WidgetRef ref) {
final jobAsync = ref.watch(jobStreamProvider(jobId));
return ScaffoldAsyncValueWidget<Job>(
value: jobAsync,
data: (job) => JobEntriesPageContents(job: job),
);
}
}DTO DAO
DTO (Data Transfer Object)
외부 통신을 위한 인터페이스 역할을 하는 것들을 다 DTO라고 보면 된다. 계층 간 데이터 교환을 하기 위해 사용하는 객체로, 로직을 가지지 않는 순수한 데이터 객체(getter & setter만 가진 클래스)이다.
DAO (Data Access Object)
DB에 접근하기 위한 객체로, DB에 접근하는 로직과 비즈니스 로직을 분리하기 위해 사용한다. DAO는 DTO를 사용하여 DB에 접근한다.
비즈니스 로직과 use case
사업자와 사용자의 차이
- 비즈니스 로직 : 서버측에서 클라이언트로 인해서 발생하는 비즈니스 로직을 처리하는 것
- use case : use case는 사용자 관점에서 시스템 기능을 재정리하는 것
Entity와 Model
나한텐 너무 어려운 개념이다. 일단 엔티티는 비즈니스 로직에서의 모델이라고 이해하고 있기로 했다.
엔티티와 모델은 같은 개념인가? 에 대한 답변
- GPT
"모델"과 "엔티티"라는 용어는 종종 상황에 따라 다르게 해석될 수 있으므로, 특정 문맥이나 프레임워크에서는 이 용어들이 어떻게 사용되는지 확인하는 것이 중요합니다. 예를 들어, MVC(Model-View-Controller) 아키텍처에서 "모델"은 보통 데이터와 비즈니스 로직을 모두 포함하도록 설계됩니다. 도메인 주도 설계(Domain-Driven Design, DDD)에서 "엔티티"는 비즈니스 로직을 중심으로 설계되며, 일반적으로 데이터베이스의 테이블을 직접적으로 반영하지 않습니다.
- Cody Yun