실행 계획
10.1 통계 정보
- 기본에는 인덱스에 대한 개괄적인 정보를 가지고 실행 계획을 수립했음 (MySQL 5.7 버전까지)
- 인덱스되지 않은 칼럼들에 대해서도 데이터 분포도를 수집해서 저장하는 것을 히스토그램이라고 함
10.1.1 테이블 및 인덱스 통계 정보
- 비용 기반 최적화에서 가장 중요한 것은 통계 정보임
- 1억 건의 레코드가 저장된 테이블의 통계 정보가 갱신되지 않아 10건 미만인 것처럼 돼 있다면 옵티마이저는 실제 쿼리를 실행할 때 인덱스 레인지 스캔이 아니라 테이블을 처음부터 끝까지 읽는 방식으로 실행해버릴 수도 있음
- 부정확한 통계 정보 탓에 0.1초에 끝날 쿼리를 1시간이 소요될 수도 있음
10.1.1.1 MySQL 서버의 통계 정보
- InnoDB 스토리지 엔진을 사용하는 테이블에 대한 통계 정보를 영구적으로 관리할 수 있게 개선됨(MySQL 5.6 버전부터)
- MySQL 5.5 버전까지는 통계 정보가 메모리에 관리되서 서버가 재시작되면 통계 정보가 초기화됨
- 통계 정보의 각 칼럼은 다음과 같은 값을 저장하고 있음
- innodb_index_stats.stat_name='n_diff_pfx%' : 인덱스가 가진 유니크한 값의 개수
- innodb_index_stats.stat_name='n_leaf_pages' : 인덱스의 리프 노드 페이지 개수
- innodb_index_stats.stat_name='size' : 인덱스 트리의 전체 페이지 개수
- innodb_table_stats.stat_name='n_rows' : 테이블의 전체 레코드 개수
- innodb_table_stats.stat_name='clustered_index_size' : 프라이머리 키의 크기(InnoDB 페이지 개수)
- innodb_table_stats.sum_of_other_index_sizes : 프라이머리 키를 제외한 인덱스의 크기(InnoDB 페이지 개수)
- innodb_stats_auto_recalc 옵션을 비활성화하면 통계 정보가 자동으로 갱신되는 것을 막을 수 있음
- 책에서는 영구적인 통계 정보를 보고 싶다면 innodb_stats_auto_recalc 옵션을 비활성화하라고 나와있지만, 실제로 innodb_stats_auto_recalc 옵션과 persistent optimizer statistics 옵션과는 관련이 없어 보임 (실제 공식 문서 내용 👇)
- STATS_AUTO_RECALC specifies whether to automatically recalculate persistent statistics. The value DEFAULT causes the persistent statistics setting for the table to be determined by the innodb_stats_auto_recalc setting. A value of 1 causes statistics to be recalculated when 10% of table data has changed. A value 0 prevents automatic recalculation for the table. When using a value of 0, use ANALYZE TABLE to recalculate statistics after making substantial changes to the table.
- STATS_AUTO_RECALC은 영구 통계를 자동으로 다시 계산할지 여부를 지정합니다. DEFAULT 값을 사용하면 테이블의 영구 통계 설정이 innodb_stats_auto_recalc 설정에 따라 결정됩니다. 1 값을 사용하면 테이블 데이터의 10%가 변경되면 통계가 다시 계산됩니다. 0 값은 테이블의 자동 재계산을 방지합니다. 0 값을 사용하는 경우 ANALYZE TABLE를 사용하여 테이블을 크게 변경한 후 통계를 다시 계산하세요.
- 참고 : https://dev.mysql.com/doc/refman/8.4/en/innodb-persistent-stats.html (opens in a new tab)
- 책에서는 영구적인 통계 정보를 보고 싶다면 innodb_stats_auto_recalc 옵션을 비활성화하라고 나와있지만, 실제로 innodb_stats_auto_recalc 옵션과 persistent optimizer statistics 옵션과는 관련이 없어 보임 (실제 공식 문서 내용 👇)
- 통계 정확도를 높이기 위해선 아래 값을 높이면 됨
- innodb_stats_persistent_sample_pages : 이 시스템 변수의 기본 값은 20이고 영구적인 통계 정보 테이블에 저장할 때 이 값을 사용해서 샘플링함
- innodb_stats_transient_sample_pages : 이 시스템 변수의 기본 값은 8인데, 이는 자동으로 메모리 통계 정보 수집이 실행될 때 8개 페이지만 임의로 샘플링해서 분석한다는 뜻임
10.1.2 히스토그램
- 히스토그램 : 칼럼의 데이터 분포도
10.1.2.1 히스토그램 정보 수집 및 삭제
- MySQL 8.0 버전에서 히스토그램 정보는 ANALYZE TABLE UPDATE HISTOGRAM 명령을 실행해서 수동으로 관리
- 히스토그램 타입
- Singleton(싱글톤 히스토그램) : 칼럼값 개별로 레코드 건수를 관리하는 히스토그램, Value-Based 히스토그램 또는 도수 분포라고 함
- 칼럼이 가지는 값별로 버킷이 할당
- 각 버킷이 칼럼의 값, 발생 빈도 비율 2개의 값을 가짐
-
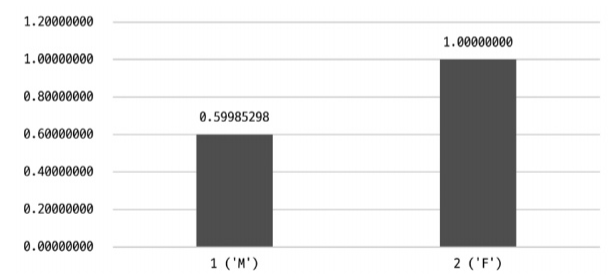
- 👆 M 값과 F 값에 대한 분포율을 담고 있으며 누적 값을 가지고 있기 때문에 F 값은 1 - M 값이 됨
- Equi-Height(높이 균형 히스토그램) : 칼럼값의 범위를 균등한 개수로 구분해서 관리하는 히스토그램
- 각 버킷이 범위 시작 값과 마지막 값, 발생 빈도율, 유니크한 값의 개수 총 4개의 값을 가짐
-
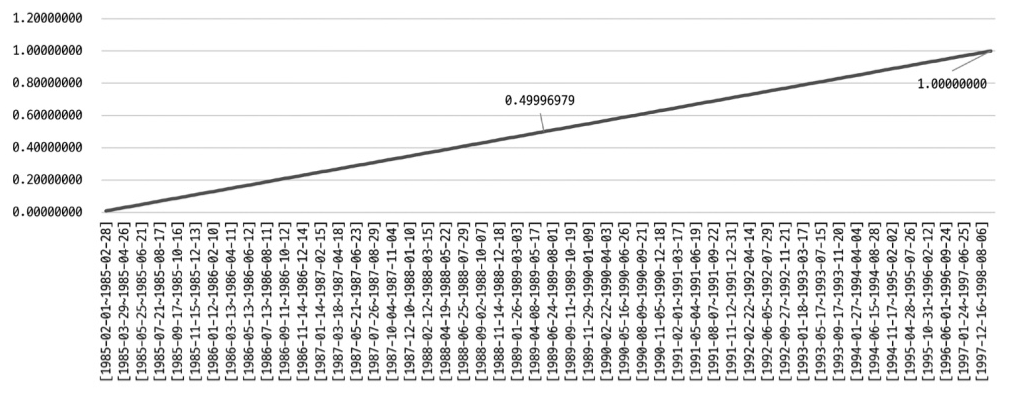
- 👆 모두 균등하게 분포되어 있는거 같지만 잘 보면 범위가 다름 - 즉 다른 범위에서 균등한 분포가 되도록 버킷을 나눈 것
- Singleton(싱글톤 히스토그램) : 칼럼값 개별로 레코드 건수를 관리하는 히스토그램, Value-Based 히스토그램 또는 도수 분포라고 함
10.1.2.2 히스토그램의 용도
- 테이블의 레코드가 1000건이고 어떤 칼럼의 유니크한 값 개수가 100개였다면 MySQL 서버는 이 칼럼에 대해 다음과 같은 동등 비교 검색을 하면 대략 10 개의 레코드가 일치할 것이라고 예측함
- 하지만 1건의 유니크한 값에 901건의 레코드가 있다면 이 예측은 아주 틀린 예측이 되는 것임
- 👉 기본적으로 데이터 분포가 균등할거라고 예측하기 때문임
- 그래서 히스토그램을 활용한 데이터 분포를 아는게 중요함