5주차: 글로벌 SNS 뉴스 피드 시스템

1. 요구사항 정의
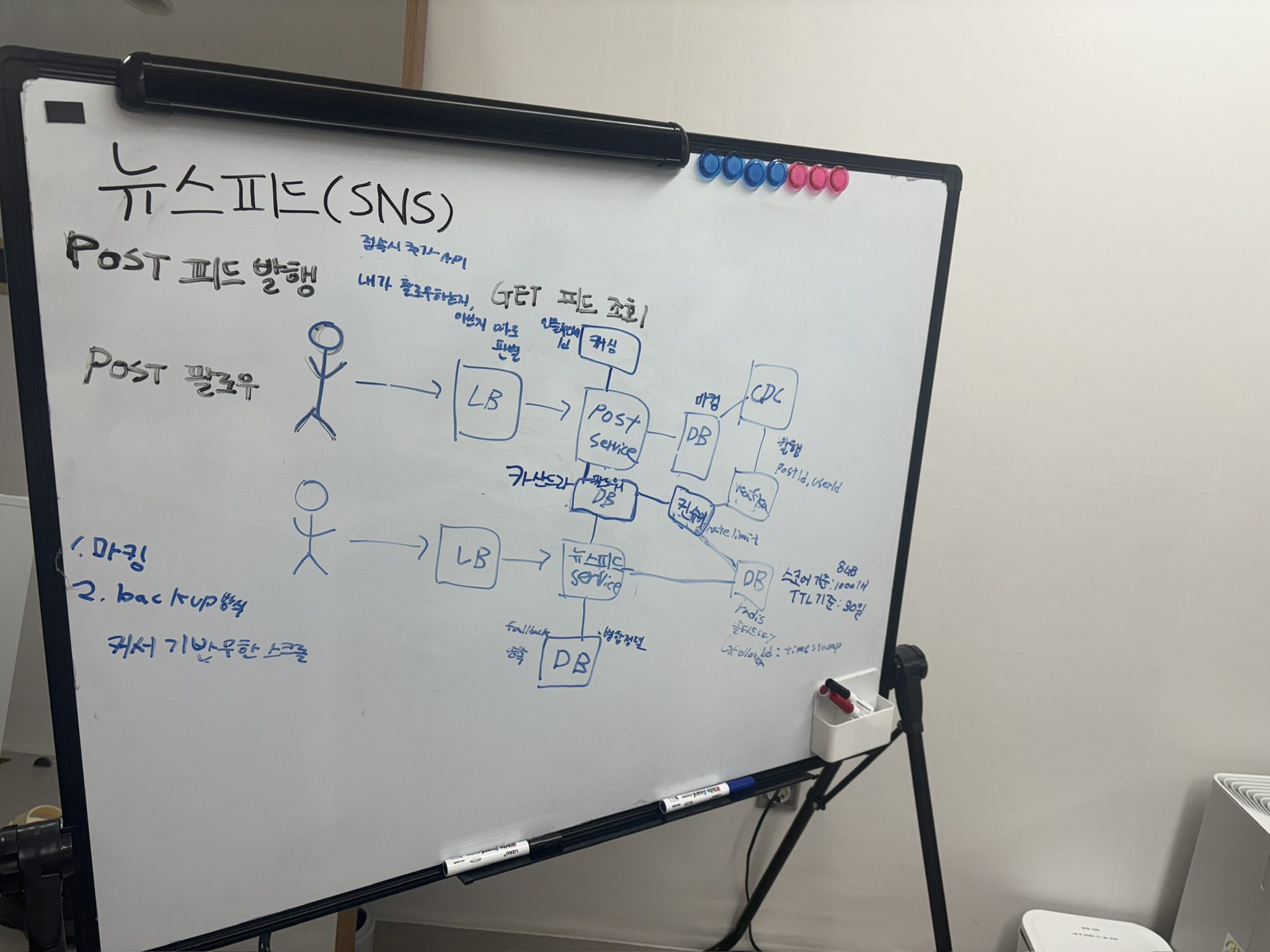
저희는 DAU 1억 명 규모의 글로벌 SNS 뉴스 피드 시스템을 설계하게 되었습니다. 기능적 요구사항으로는 팔로우하는 사용자의 글을 시간 역순으로 보여주는 피드 생성, 텍스트와 미디어를 포함한 포스팅, 그리고 사용자 간 팔로우/언팔로우 기능이 포함되었습니다.
비기능적 요구사항에는 읽기 응답 속도 200ms 이하, 쓰기 응답 속도 500ms 이하로 정의했습니다. 이는 매우 중요한 제약 조건이었고, Eventual Consistency는 허용하되 높은 가용성을 보장해야 했습니다.
규모 추정을 할 때는 DAU 100M을 기준으로 계산했습니다. Read QPS는 약 5,800~30,000 (Peak), Write QPS는 약 230~1,150 (Peak)으로 산출되었고, 읽기:쓰기 비율이 100:1인 전형적인 Read-Heavy System이라는 것을 확인할 수 있었습니다. 일일 약 6TB의 데이터가 생성될 것으로 예상되었습니다.
2. 아키텍처: Push vs Pull
처음에 저희는 읽기 지연 200ms를 달성하기 위해서 어떤 방식을 사용할지 고민했습니다. 크게 Pull Model (Fan-out on Read)과 Push Model (Fan-out on Write) 두 가지 방식을 논의했습니다.
Pull Model을 먼저 검토했는데, 조회 시점에 SELECT * FROM posts WHERE user_id IN (friends...)처럼 데이터를 가져오는 방식이었습니다. 하지만 이 방식은 몇 가지 문제가 있었습니다:
- 조회 시점에 발생하는 Random I/O가 너무 많았습니다
- 수천 명의 친구 데이터를 가져와서 메모리에서 정렬(Merge Sort)하는 비용이 컸습니다
- DB 샤딩 환경에서 Scatter-Gather 때문에 성능이 크게 떨어졌습니다
결국 저희는 Push Model (Fan-out on Write)을 채택했습니다. Write 시점에는 조금 더 복잡하지만, Read 시점에는 연산 없이 캐시만 읽어서 O(1)로 반환할 수 있다는 점이 200ms 제약을 만족하는 데 결정적이었습니다. 읽기 성능을 극대화하기 위해 쓰기 시점의 복잡도를 감수하는 것이 옳은 선택이라는 결론이 났습니다.
3. CDC 기반 비동기 아키텍처
Push Model을 안정적으로 처리하기 위해서는 Fan-out 작업이 애플리케이션 성능에 영향을 주지 않아야 했습니다. 이를 위해 CDC (Change Data Capture) 기반의 비동기 아키텍처를 도입했습니다.
데이터 흐름은 다음과 같이 설계했습니다:
- Post Service: 사용자가 글을 쓰면 RDB에 저장(
INSERT)하고 즉시 응답을 반환합니다. 이렇게 해서 Write Latency를 최소화했습니다. - CDC (Debezium): DB의 Transaction Log(Binlog)를 감지해서 Kafka로 이벤트를 발행합니다. 이 방식의 장점은 애플리케이션과의 결합도를 완전히 제거하면서도 이벤트 누락을 방지할 수 있다는 점이었습니다.
- Fan-out Worker: Kafka에서 이벤트를 소비하여 팔로워 목록을 조회하고, 각 팔로워의 Redis ZSET에 포스팅 ID를 추가(
ZADD)합니다. 여기서는 Redis Pipeline을 사용해서 대량의 쓰기 작업을 배치 처리했습니다.
캐시 전략으로는 Redis Sorted Set (ZSET)을 선택했습니다. Key는 feed:{user_id}, Score는 timestamp, Value는 post_id 형태로 저장했습니다. 메모리 효율을 위해 최신 800개만 유지하고, 801번째부터는 DB에서 조회하는 Hybrid Pagination 방식을 사용했습니다. 또한 미접속 유저의 캐시 낭비를 막기 위해 2주(14일) TTL을 설정했고, 조회 시에는 갱신(Renew)하도록 했습니다.
장애 대응도 중요했는데, Cache Miss가 발생하면 DB에서 직접 조회해서 캐시를 재구축(Reconstruct)하도록 했습니다. 다만 동시 요청이 폭주하는 Thundering Herd를 막기 위해 Local Lock을 적용하고 조회 범위를 최신 20개로 제한했습니다.
페이지네이션 전략: Offset vs Cursor
페이지네이션 구현 방식을 논의할 때, 처음에는 Offset 기반과 Cursor 기반 두 가지 방식을 고민했습니다. 예를 들어 사용자가 500명의 팔로워를 가지고 있다면, 그 중에서 처음에는 10~20명 정도의 게시물만 조회해서 피드를 보여주는 방식이었습니다.
Offset 기반의 문제점
처음에는 Offset 기반(ZREVRANGE)이 간단해 보였습니다. ZREVRANGE는 rank(순위) 기반으로 조회하는 명령어인데, Redis ZSET 내부적으로는 timestamp(score) 순으로 정렬되어 있습니다. 이 차이 때문에 중요한 문제를 발견했습니다:
Offset 방식의 핵심 문제는 rank(순위)로 조회하지만, 내부적으로는 timestamp로 정렬된다는 점입니다. 사용자가 첫 페이지를 보고 두 번째 페이지로 넘어가는 사이에 새로운 게시물이 추가되면:
- timestamp 기준으로 재정렬이 일어나면서 모든 게시물의 rank가 변경됩니다
- 이전에 Rank 1이었던 Post4가 Rank 2로 밀립니다
- 두 번째 요청에서 Rank 2~3을 조회하면 Post4가 다시 나타납니다
Feed의 순서가 재정렬되면서 다음 offset에 이전 데이터가 포함될 수 있는 문제가 발생하는 것이었습니다.
Cursor 기반의 해결
결국 Cursor 기반 (Timestamp/Score 기반)을 채택했습니다. ZREVRANGEBYSCORE를 사용하면 "이 시간(Score) 이전" 데이터를 조회하는 방식이라 중복 문제를 해결할 수 있었습니다:
하지만 이 때 중요한 문제를 발견했습니다. Cursor 기반에서는 첫 번째 조회와 두 번째 조회 사이에 추가된 데이터가 누락될 수 있다는 것이었습니다:
이건 기획팀과 얘기를 해봐야겠지만, 저희는 이 정도의 데이터 누락은 사용자 경험을 크게 해치지 않는 범위일 것 같다고 생각했습니다. SNS 피드 특성상 실시간으로 계속 새로운 게시물이 추가되는데, 사용자가 스크롤하는 동안 추가된 일부 게시물이 누락되는 것은 충분히 용인할 수 있는 트레이드오프였습니다. 오히려 중복 노출이 사용자 경험에 더 부정적이라는 결론이 났습니다.
Redis 명령어 구현
실제 Redis 구현에서는 다음과 같은 명령어를 사용했습니다:
1. Offset 기반 방식 (권장하지 않음)
# Redis 6.2.0 이전 방식 (deprecated)
ZREVRANGE feed:user123 0 19
# Redis 6.2.0 이상 권장 방식
ZRANGE feed:user123 0 19 REV출처: Redis ZREVRANGE Documentation (opens in a new tab)
참고: Redis 6.2.0부터
ZREVRANGE는 deprecated되었으며,ZRANGEwithREV옵션 사용이 권장됩니다.
2. Cursor 기반 방식 (채택)
# 첫 페이지 조회 (deprecated 방식 - Redis 6.2.0 이전)
ZREVRANGEBYSCORE feed:user123 +inf -inf WITHSCORES LIMIT 0 20
# 반환 예시: [("post_id_100", 1699999999), ("post_id_99", 1699999998), ...]
# 다음 페이지 조회 (cursor = 1699999998)
# "(" 기호는 exclusive(미포함)을 의미
ZREVRANGEBYSCORE feed:user123 (1699999998 -inf WITHSCORES LIMIT 0 20# Redis 6.2.0 이상 권장 방식 (ZRANGE with options)
# 옵션 설명:
# - BYSCORE: score 기준으로 범위 조회 (index가 아닌 score 값으로)
# - REV: 역순 정렬 (높은 score → 낮은 score, 최신순)
# - WITHSCORES: score 값도 함께 반환
# - LIMIT offset count: 결과 중 offset부터 count개만 반환
# 첫 페이지 조회 (가장 최신 20개)
# +inf부터 -inf까지 = 모든 score 범위
ZRANGE feed:user123 +inf -inf BYSCORE REV WITHSCORES LIMIT 0 20
# 반환 예시: [("post_id_100", 1699999999), ("post_id_99", 1699999998), ...]
# 다음 페이지 조회 (cursor = 1699999998 이전 데이터)
# "(1699999998"은 exclusive bound (해당 score 미포함)
ZRANGE feed:user123 (1699999998 -inf BYSCORE REV WITHSCORES LIMIT 0 20출처: Redis ZREVRANGEBYSCORE Documentation (opens in a new tab)
참고: Redis 6.2.0부터
ZREVRANGEBYSCORE는 deprecated되었으며,ZRANGEwithREV,BYSCORE옵션 사용이 권장됩니다.
3. 실제 코드 예시 (Python)
# 첫 페이지 조회
def get_first_page(user_id, limit=20):
feed_key = f"feed:{user_id}"
# ZRANGE with REV, BYSCORE (Redis 6.2.0+)
results = redis.zrange(
feed_key,
'+inf',
'-inf',
byscore=True,
rev=True,
withscores=True,
start=0,
num=limit
)
if not results:
return [], None
# 마지막 아이템의 score를 cursor로 반환
cursor = results[-1][1] # (post_id, score)
return results, cursor
# 다음 페이지 조회
def get_next_page(user_id, cursor, limit=20):
feed_key = f"feed:{user_id}"
# cursor보다 작은 값만 조회 (exclusive)
results = redis.zrange(
feed_key,
f'({cursor}', # exclusive: cursor 미포함
'-inf',
byscore=True,
rev=True,
withscores=True,
start=0,
num=limit
)
if not results:
return [], None
new_cursor = results[-1][1]
return results, new_cursor
**Timestamp 기준의 Cursor 방식을 사용함으로써 Feed 재정렬 시 중복 문제를 해결하면서도, 약간의 데이터 누락은 사용자 경험 관점에서 용인할 수 있는 합리적인 설계**를 할 수 있었습니다.
### 4. 유명인(Celebrity) 처리와 Hybrid 아키텍처
시스템을 설계하다 보니 중요한 문제를 발견했습니다. 팔로워가 수백만 명인 VIP(Hotkey)의 글을 Push 방식으로 처리하면 시스템에 심각한 지연(Lag)이 발생한다는 것이었습니다. 이 문제를 해결하기 위해 **Hybrid Model**을 도입했습니다.
먼저 VIP 기준을 팔로워 50만 명 이상으로 정했고, User Metadata나 Graph DB의 `is_vip` 플래그로 식별하기로 했습니다. 그리고 처리 전략을 다르게 가져갔습니다:
- **일반 유저 (Push)**: 기존대로 팔로워 피드에 직접 배달
- **VIP (Pull)**: 팔로워 피드에 배달하지 않고, VIP 전용 캐시(`vip_posts:{vip_id}`)에만 저장
이렇게 하면 읽기 로직이 조금 복잡해집니다. 사용자가 피드를 조회할 때(`GET /feed`) 다음 과정을 거치게 됩니다:
1. **Native Feed**: 내 Redis 피드(`feed:{my_id}`) 조회
2. **VIP Feed**: 내가 팔로우하는 VIP 목록(`following_vips:{my_id}`)을 확인 후, 각 VIP의 전용 캐시 조회
3. **Merge**: 애플리케이션 메모리에서 두 리스트를 합쳐 시간순 정렬 후 반환
읽기 시점에 약간의 복잡도가 생기지만, VIP의 글 작성 시 수백만 건의 Fan-out을 방지할 수 있다는 점에서 합리적인 트레이드오프라고 판단했습니다.
### 5. 데이터 저장소 전략: Cassandra 선택
500억 건(1억 유저 × 500 팔로우) 이상의 관계(Relationship) 데이터를 어떻게 저장할지 고민했습니다. 처음에는 RDB를 생각했지만, 결국 Wide-Column Store인 **Cassandra**를 선택했습니다.
RDB 대신 Cassandra를 선택한 이유는 **I/O 패턴**의 차이 때문이었습니다. RDB는 팔로워를 조회할 때 인덱스를 타고 여기저기 뒤져야 하는 **Random I/O**가 발생합니다. 하지만 Cassandra는 Partition Key(`user_id`) 기준으로 데이터가 물리적으로 인접해 있어서(Wide Row), **단 한 번의 Seek**로 500명을 읽어올 수 있습니다. 이것이 **Sequential I/O**의 힘이었습니다.
또한 데이터 양이 증가할 때 노드만 추가하면 선형적으로 성능이 확장(Linear Scalability)되는 것도 큰 장점이었습니다.
데이터 모델링에서는 **Denormalization**을 적극 활용했습니다. `Followers` 테이블(Fan-out용)과 `Followings` 테이블(View용)을 따로 두었고, `Followings` 테이블에 **`is_vip` (Boolean)** 컬럼을 추가해서 팔로우 목록 조회 시 별도 쿼리 없이 VIP 여부를 즉시 식별할 수 있도록 최적화했습니다.
**NoSQL의 Sequential Access 특성을 활용하면 대규모 관계 데이터도 효율적으로 처리할 수 있다**는 것을 배울 수 있었습니다.
### 6. 엣지 케이스: VIP 탈퇴 처리
흥미로운 엣지 케이스가 있었습니다. 1억 명의 팔로워를 가진 VIP가 탈퇴하면 어떻게 해야 할까요? 모든 팔로워 데이터를 즉시 삭제하면 시스템에 큰 부하가 걸립니다. 이를 해결하기 위해 **"Fast Hide, Slow Clean"** 전략을 사용했습니다.
먼저 **Fast Hide (동기 처리**)로 사용자 입장에서는 즉시 효과가 나타나도록 했습니다:
- User DB status를 `DELETED`로 변경
- Redis `vip_posts:{id}`를 즉시 삭제하거나 **Tombstone 마킹**: 데이터를 물리적으로 삭제하는 대신 `{deleted: true, deleted_at: timestamp}` 같은 메타데이터를 추가하여 "논리적 삭제" 상태로 표시합니다. 이렇게 하면 조회 시점에 해당 데이터를 필터링할 수 있으면서도, 삭제 작업으로 인한 즉각적인 부하를 피할 수 있습니다.
그리고 **Read-time Defense**를 추가했습니다. 이는 읽기 시점에 방어적으로 데이터를 검증하는 패턴으로, 비동기 삭제가 완료되지 않은 상태에서도 사용자에게 올바른 데이터만 보여주는 역할을 합니다:
- 피드 조회 시 VIP 캐시가 없거나 Tombstone이면 결과에서 제외
- 조회한 유저의 `following_vips` 목록에서 해당 VIP 제거 (**Self-Repair**): 읽기 요청 시 무효한 데이터를 발견하면 그 자리에서 정리하는 방식입니다. 별도의 배치 작업 없이도 자연스럽게 데이터가 정리되며, 활성 사용자의 데이터부터 우선적으로 정리되는 효과가 있습니다.
마지막으로 **Slow Clean (비동기 처리**)로 별도의 Cleanup Worker가 Cassandra 팔로워 목록을 천천히 스캔하며 데이터를 물리적으로 삭제하도록 했습니다. 이때 Rate Limiting을 적용해서 시스템 부하를 최소화했습니다.
**사용자 경험과 시스템 안정성을 모두 고려한 비동기 처리 전략**의 좋은 예시였던 것 같습니다.
### 7. 결론
저희는 이번 설계를 통해 몇 가지 중요한 인사이트를 얻을 수 있었습니다:
1. **읽기 성능의 극대화**를 위해서는 쓰기 시점의 복잡도(Push Model)를 감수할 수 있어야 합니다.
2. **규모의 비대칭성(Celebrity 문제**)은 Hybrid 방식으로 해결할 수 있습니다.
3. **NoSQL의 Sequential Access** 특성을 활용하면 대규모 데이터의 I/O 효율성을 크게 높일 수 있습니다.
4. **CDC와 비동기 처리**를 통해 애플리케이션 결합도를 낮추면서도 안정적인 이벤트 처리가 가능합니다.
5. **페이지네이션 방식 선택**은 사용자 경험(중복 vs 누락)과 기술적 제약(Feed 재정렬)을 모두 고려해야 합니다.
정확한 수학적 근거(QPS 계산, 경우의 수 산출)를 기반으로 판단하고, I/O 패턴과 같은 본질적인 차이를 이해하는 것이 얼마나 중요한지 배울 수 있었습니다. 이를 통해 1억 DAU 환경에서도 안정적으로 200ms 이내의 읽기 응답 속도를 보장하는 시스템을 구축할 수 있었습니다.